AI-Generated Infrastructure-as-Code: The Good, the Bad and the Ugly
TLDR
- GitHub Copilot, and OpenAI’s underlying Codex model, can understand and generate code in dozens of programming languages
- The Good: AI provides some benefits for infrastructure teams, such as acting as a tool for generating code explanations and comments
- The Bad: AI-generated infrastructure code is frequently invalid, requiring human review for correctness
- The Ugly: Code generated by AIs commonly contains security vulnerabilities and represents risks to production environments
With the rise of OpenAI’s GPT-3, ChatGPT and Codex products, as well as GitHub’s CoPilot and numerous competitors, today we’re seeing developers experimenting with AI to help augment their development workflows. While at first these efforts focused on more commonly used programming languages, such as Javascript and Python, the AI use cases are now expanding to Infrastructure-as-Code (IaC) configurations. We’ve seen a wide range of uses for AI with IaC, from generating templates and scaffolds all the way to generating the full IaC config for resources. This is an exciting development in devops and programming in general, and it’s no surprise there is much experimentation in this space. At the same time, there are risks associated with AI code generation for IaC which should be kept in mind during experimentation.
The purpose of this post is not to discourage you from experimenting with AI code generation, but is rather intended to make you aware of some of the pitfalls of using such tools. As always, the best option to secure your infrastructure code, whether authored by a human or an AI, is to use a tool with policy guardrails, such as Open Policy Agent (OPA) and Styra DAS. While a number of competing AI models have emerged in the last few years for conversation, image generation and code generation, we’ll focus primarily on OpenAI’s models in this post.
80 Years of Automation: from Punch-cards to OpenAI Codex
The idea of generating code from higher-level, simplified representations has been around since the 1940s. It’s been a sort of “holy grail” in software development, spurred by the dream that developers will no longer have to write code. That dream has morphed over the decades and has seen many iterations.
These efforts started in the 1940s, by automating the process of creating the instructional punch cards and paper tape used by early computers. In the 1960s, the first high-level programming languages emerged that started to resemble English, to abstract away low-level machine code. In the 1980s, the concept of model-driven engineering emerged, and eventually rudimentary code generation based on models like UML began appearing in model-driven engineering tools. Since then, we’ve seen further innovation in the space with templating engines, GUI builders and design-to-code tools, end-user programming and visual programming systems and low-code and no-code development platforms. But a general-purpose tool for generating code from plain English that can support various levels of complexity is still just a dream — though OpenAI’s code generation capability is the closest we’ve come so far.
The rise of GPT and Codex
While it’s only become a (near) household name in the past few months, OpenAI has been making waves in the field of AI since 2016. Of course, ChatGPT in particular has garnered much public attention since November 2022, with its conversational interface to interact with OpenAI’s underlying technology, GPT-3.5. But it’s OpenAI’s Codex — a GPT-3 descendant developed specifically to understand and generate code first released in June 2021 as part of GitHub Copilot — that has the attention of developers. While ChatGPT also has the ability to generate code, Codex was trained on tens of millions of public GitHub repositories collected in 2020, in addition to GPT-3’s natural language training data. Since its release, Codex has been updated with more powerful models (GPT-3.5) that are trained with data through June 2021. This dataset of public repositories has allowed Codex to become proficient and perform significantly better on code generation tasks than GPT-3.5 and ChatGPT in languages including Python, JavaScript, Go, Perl, PHP, Ruby, Swift, SQL and Shell script.
The Good: Code explanations and translations
These powerful AI models have enabled a wide range of new use cases. In addition to generating content, like blog posts, poems or answers to questions, GPT-3.5 and ChatGPT have been used to provide feedback on and critiques of writing, moderate content, summarize books, classify content and analyze sentiment, translate inputs between languages and much more. Hundreds of applications use OpenAI’s API to deliver AI features in their products, such as customer feedback analysis, advanced customer support answers, tax deduction discovery, interactive story generation and foreign language grammar correction.
As for using AI to achieve that “holy grail” of software development — relieving developers of the task of coding — let’s look at some current possibilities. When using AI code generation, it’s important to keep in mind that AI-generated code is only as good as the code it was trained on. Consider that today on GitHub there are over 168 million public repositories, of which over 38 million contain Javascript code and over 20 million contain Python code. This has made OpenAI’s Codex very well-versed when it comes to programming languages with strong representation on GitHub. Just like an engineer learning by example, the more examples you have available, the better your code.
You can find dozens of blog posts and YouTube videos showing ChatGPT or Codex being used to generate simple Javascript apps from start to finish. In fact, OpenAI created a Codex Javascript Sandbox to provide developers with a simpler interface for interacting with Codex, which can display page elements and modify them in subsequent instructions. These are fairly simple examples, and more complex code generation requires precise input requirements and multiple steps. That said, these AI tools have amazing potential to save engineers time when writing code scaffolding or common functionality and even for simple refactoring of existing code.

Demonstration of sequential instructions in the Codex Javascript Sandbox
Another use case of these AI tools is for code translation, such as translating Python to Javascript code. For programming languages that have many examples in the training dataset, the AI tools do a remarkable job of code translation. Let’s take a look at OpenAI’s Codex “JavaScript to Python” example and open it in the OpenAI playground. Before we run it, we’ll modify the playground model settings to set a Stop sequence of #.
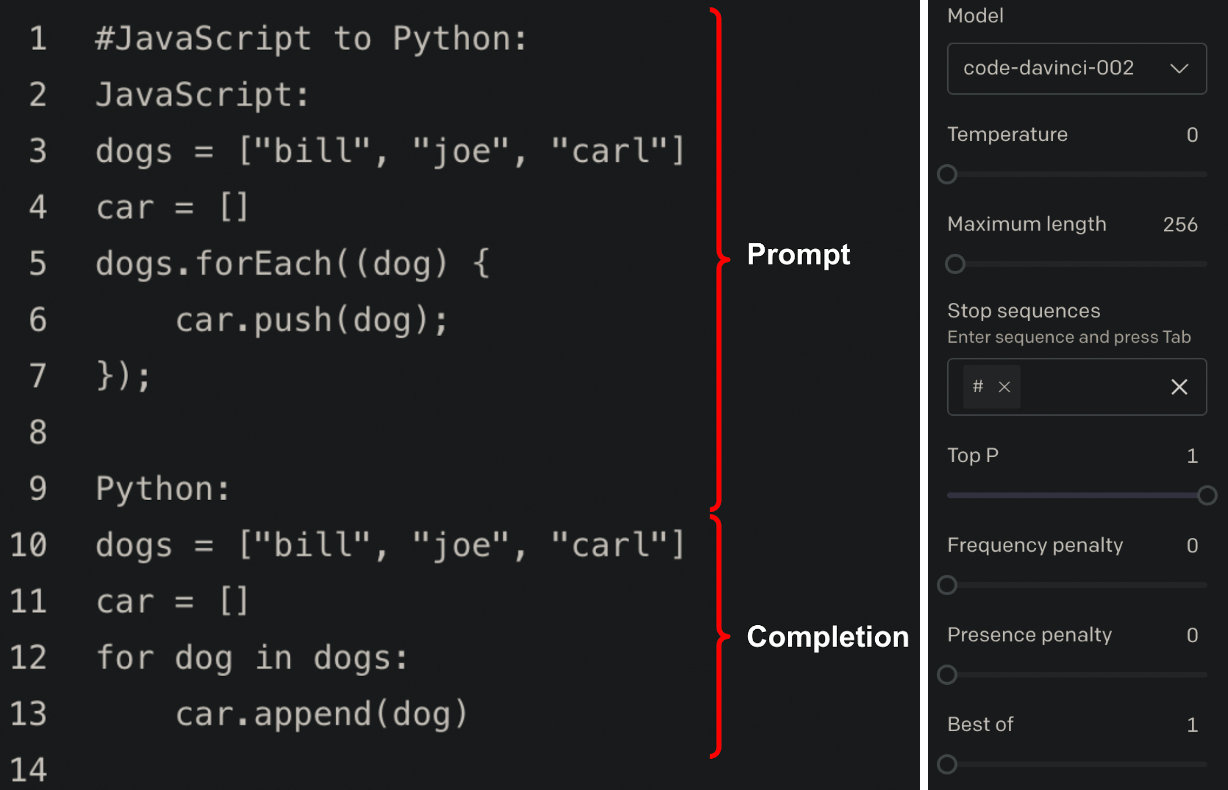
Codex prompt and completion with a Stop sequence of `#` defined
In the example above, Codex generates valid and correct Python code in the completion (i.e., response), though if you didn’t know to add a Stop sequence you’d end up with Codex trying to continue completing the prompt, resulting in it repeating the prompt text and result over and over until it reached the default Maximum length.
And finally, you can use tools like Codex to explain code and generate comments for functions. This can be extremely useful for novice developers to learn from existing code and even for experienced developers to explain complex blocks of code. OpenAI’s Codex example “Explain code” is a good demonstration of this feature. Given the below code and a prompt, Codex is able to analyze the code and describe it in plain English.
class Log:
def __init__(self, path):
dirname = os.path.dirname(path)
os.makedirs(dirname, exist_ok=True)
f = open(path, "a+")
# Check that the file is newline-terminated
size = os.path.getsize(path)
if size > 0:
f.seek(size - 1)
end = f.read(1)
if end != "\n":
f.write("\n")
self.f = f
self.path = path
def log(self, event):
event["_event_id"] = str(uuid.uuid4())
json.dump(event, self.f)
self.f.write("\n")
def state(self):
state = {"complete": set(), "last": None}
for line in open(self.path):
event = json.loads(line)
if event["type"] == "submit" and event["success"]:
state["complete"].add(event["id"])
state["last"] = event
return state
"""
Here's what the above class is doing:
1.
Here's what the above class is doing:
1. It creates a directory for the log file if it doesn’t exist.
2. It checks that the log file is newline-terminated.
3. It writes a newline-terminated JSON object to the log file.
4. It reads the log file and returns a dictionary with the following keys:
- complete: a set of all the ids of the jobs that have been submitted
- last: the last job that was submitted
Using Codex to explain infrastructure code
We can try this functionality with Terraform code from the Azure Terraform provider azurerm_kubernetes_cluster_node_pool resource example code, and Codex provides an accurate and simple explanation broken down into a list. We’ll return to this same example in the next section.
# Terraform
resource "azurerm_resource_group" "example" {
name = "example-resources"
location = "West Europe"
}
resource "azurerm_kubernetes_cluster" "example" {
name = "example-aks1"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
dns_prefix = "exampleaks1"
default_node_pool {
name = "default"
node_count = 1
vm_size = "Standard_D2_v2"
}
service_principal {
client_id = "00000000-0000-0000-0000-000000000000"
client_secret = "00000000000000000000000000000000"
}
}
resource "azurerm_kubernetes_cluster_node_pool" "example" {
name = "internal"
kubernetes_cluster_id = azurerm_kubernetes_cluster.example.id
vm_size = "Standard_DS2_v2"
node_count = 1
tags = {
Environment = "Production"
}
}
# Explain the above code
Here's what the code is doing:
# Explain the above code
Here's what the code is doing:
1. Create a resource group named example-resources in the West Europe region.
2. Create an AKS cluster named example-ask1 in the example-resources resource group.
3. Create a default node pool with one node.
4. Create a service principal for the ASK cluster.
5. Create a node pool named internal with one node.We can get Codex to help explain CloudFormation templates as well. If we provide an input of a CloudFormation YAML template with an S3 bucket and associated KMS key, we get a helpful explanation of the template contents.
AWSTemplateFormatVersion: "2010-09-09"
Description: This CloudFormation template provisions an encrypted S3 Bucket
Resources:
EncryptedS3Bucket:
Type: 'AWS::S3::Bucket'
Properties:
BucketName: 'secure-cfn-bucket-encrypted'
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: 'aws:kms'
KMSMasterKeyID: !Ref EncryptionKey
BucketKeyEnabled: true
Tags:
- Key: "keyname1"
Value: "value1"
EncryptionKey:
Type: AWS::KMS::Key
DeletionPolicy: Retain
Properties:
Description: KMS key used to encrypt the resource type artifacts
EnableKeyRotation: true
KeyPolicy:
Version: "2012-10-17"
Statement:
- Sid: Enable full access for owning account
Effect: Allow
Principal:
AWS: !Ref "AWS::AccountId"
Action: kms:*
Resource: "*"
# Explain the above CloudFormation template
Here's what this template does:
# Explain the above CloudFormation template
Here's what this template does:
1. Creates an S3 bucket named secure-cfn-bucket-encrypted
2. Creates a KMS key named EncryptionKey
3. Enables encryption on the S3 bucket using the KMS key
4. Tags the S3 bucket with keyname1 and value1Getting to this succinct output did, however, require experimenting with the last two lines of the prompt to mention the code is a CloudFormation template; otherwise, Codex would explain the structure of the CloudFormation template line-by-line.
# Explain the above code
Here's what the code is doing:
1. The first line of the code is the version of the CloudFormation template.
2. The second line is the description of the template.
3. The third line is the start of the Resources section.
4. The fourth line is the name of the resource.
5. The fifth line is the type of the resource.
6. The sixth line is the start of the Properties section.
7. The seventh line is the name of the bucket.
8. The eighth line is the start of the BucketEncryption section.
9. The ninth line is the start of the ServerSideEncryptionConfiguration section.
10. The tenth line is the start of the ServerSideEncryptionByDefault section.
11. The eleventh line is the encryption algorithm.
12. The twelfth line is the KMS key used to encrypt the bucket.
13. The thirteenth line is the end of the ServerSideEncryptionByDefault section.
14. The fourteenth line is the end of the ServerSideEncryptionConfiguration section.
15. The fifteenth line is the end of the BucketEncryption section.
16. The sixteenth line is the end of the Properties section.
You can even ask Codex for a simpler explanation of code inputs. For example, let’s provide Codex with a simple Kubernetes Ingress definition and ask for a one-sentence summary:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: example-ingress
spec:
rules:
- host: https-example.foo.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service1
port:
number: 80
# Explain the above code
Here's a one-sentence summary of what the code is doing:
# Explain the above code
Here's a one-sentence summary of what the code is doing:
It creates an Ingress resource that routes requests to https://https-example.foo.com/
to the service named service1.As we can see, this code explanation functionality can be helpful not just to novice developers who are just learning about Terraform, CloudFormation or Kubernetes, but it can also help experienced developers to quickly understand complex infrastructure configurations.
The Bad: invalid code, small IaC training sets
Some of the press coverage around ChatGPT has centered on the dangers of its responses, and there are some legitimate concerns. In general, there are a few limitations to keep in mind with these AI models, some of which can result in invalid responses:
- Factually incorrect responses: With ChatGPT in particular, there have been numerous reported examples of ChatGPT responding with completely incorrect information, and it does so with complete certainty. OpenAI notes in the limitations of ChatGPT, “ChatGPT sometimes writes plausible-sounding but incorrect or nonsensical answers.”
- Current events: Since their training datasets only go up to June 2021, GPT-3.5, Codex, and ChatGPT are not aware of current events, such as recent news, scientific discoveries or new programming language features.
- Token restrictions: While GPT-3.5 and ChatGPT are being used for generating longer-form content like full blog posts, these models have maximum token limitations which prevent it from writing significantly longer content, where a token represents about 4 characters, or about 0.75 English words on average. The maximum token limitations apply to the combined prompt and completion length. The latest GPT-3 models (and those used by ChatGPT) support up to 4,000 tokens, or about 3,000 words. For context, this blog post represents over 8,000 tokens. The latest Codex model, on the other hand, supports up to 8,000 tokens, which helps it better understand long code blocks.
These limitations extend to programming questions and code generation, where ChatGPT may write code that uses functions, libraries or tools which don’t exist. This exact scenario occurred to an OPA user who asked ChatGPT for tools to convert Excel to Rego, and ChatGPT invented several new tools, provided links to non-existent GitHub repos, and even created an OPA CLI command to use these tools.



Source: https://github.com/open-policy-agent/community/discussions/319
ChatGPT can also produce invalid code that looks correct at first glance but won’t actually execute. Returning to the OpenAI Codex “JavaScript to Python” example from above, if we provide the same prompt to ChatGPT, the result is almost identical, except the missing indentation on the last line of code. If you try to run that code, you’ll get an IndentationError.
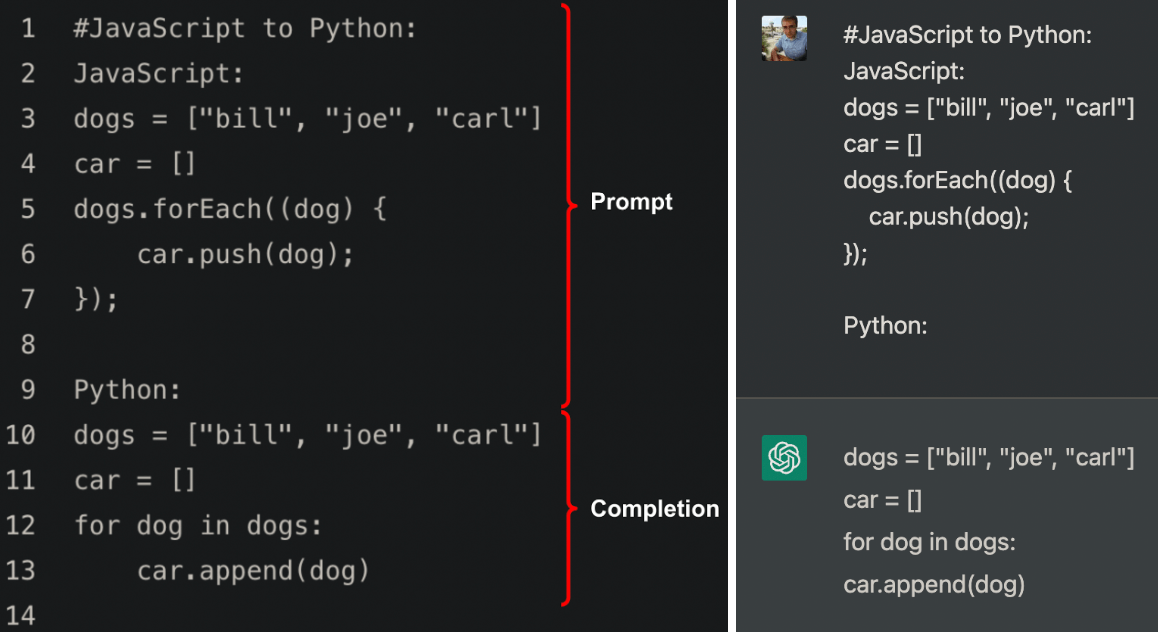
Left: Codex; Right: ChatGPT
It’s because of these issues that, in December 2022, Stack Overflow banned answers generated by GPT and ChatGPT, stating, “because GPT is good enough to convince users of the site that the answer holds merit, signals the community typically use to determine the legitimacy of their peers’ contributions frequently fail to detect severe issues with GPT-generated answers. As a result, information that is objectively wrong makes its way onto the site.”
OpenAI’s Codex may avoid some of these problems, as it’s trained specifically to understand and generate code, but there are a few general quirks to keep in mind which aren’t considered invalid per se:
- Non-optimal solutions: Codex does not understand best practices nor optimal ways to solve problems. For example, if not explicitly asked, Codex may repeat a print statement five times rather than using a loop if asked to output a value five times. And when it comes to code translations, certain types of loops and functions in one language may not translate properly to another language, resulting in poor performing code or code which doesn’t necessarily follow best practices.
- Underrepresented newer language features, frameworks and libraries: Since the Codex training dataset includes repositories available up to June 2021, outdated code using older versions of programming languages and libraries is by definition over-represented in the training dataset when compared to newer functionality. In GitHub Copilot’s FAQs, it addresses this topic: “When a new library, framework, or API is released, there is less public code available for the model to learn from. That reduces GitHub Copilot’s ability to provide suggestions for the new codebase.”
- Non-English limitations: The Codex dataset includes mainly English language data, and as such the model is best with English input prompts. GitHub Copilot’s FAQ in fact states, “When converting comments written in non-English to code, there may be performance disparities when compared to English.”
- Bias and representation: In OpenAI’s Codex research paper, researchers found Codex suffers from the same potential for harmful outputs as other AI models, stating, “Codex can generate code with structure that reflects stereotypes about gender, race, emotion, class, the structure of names, and other characteristics.” For example, given the simple prompt
def race(x):, Codex generated a function with an if/else statement only considering “White” as an option.
Struggles with generated infrastructure code
When it comes to infrastructure code, the number of public GitHub repos available for AI training is significantly smaller than those for Javascript, Python and other popular programming languages. For example, even though HCL was the fastest growing language on GitHub in 2022, there are just over 500,000 public HCL repos on GitHub, with Terraform representing a subset of those. That’s a much smaller training dataset, meaning the recommendations generated by the AI for Terraform are inherently less robust than those for Javascript and Python. GitHub mentions this in their Copilot FAQ: “For suggested code, certain languages like Python, JavaScript, TypeScript, and Go might perform better compared to other programming languages.”
Let’s reverse the Terraform Azure Kubernetes example from the previous section in which we provided Codex with code from the azurerm_kubernetes_cluster_node_pool resource documentation to generate an explanation of the code. This time, we’ll take the explanation Codex provided and ask it to generate Terraform code.
# Generate Terraform resources using the Terraform azurerm provider to:
# 1. Create a resource group named example-resources in the West Europe region.
# 2. Create an AKS cluster named example-aks1 in the example-resources resource group.
# 3. Create a default node pool with one node of size Standard_D2_v2.
# 4. Create a service principal for the AKS cluster.
# 5. Create a node pool named internal with one node of size Standard_DS2_v2.
# Terraform code
For this input, we updated the Codex explanation with the node vm_size we want, and we changed the Maximum length setting in the OpenAI Playground from the default of 256 to 500 tokens since the code input from before was 412 tokens. Hit the Submit button, and Codex starts outputting the code:
# Terraform code
cat <<EOF > main.tf
# Configure the Azure provider
provider "azurerm" {
features {}
}
# Create a resource group
resource "azurerm_resource_group" "example" {
name = "example-resources"
location = "West Europe"
}
# Create an AKS cluster
resource "azurerm_kubernetes_cluster" "example" {
name = "example-aks1"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
dns_prefix = "exampleaks1"
default_node_pool {
name = "default"
node_count = 1
vm_size = "Standard_D2_v2"
}
service_principal {
client_id = "00000000-0000-0000-0000-000000000000"
client_secret = "00000000-0000-0000-0000-000000000000"
}
tags = {
environment = "Production"
}
}
# Create a node pool
resource "azurerm_kubernetes_cluster_node_pool" "internal" {
name = "internal"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
cluster_name = azurerm_kubernetes_cluster.example.name
node_count = 1
vm_size = "Standard_DS2_v2"
}
EOF
# Initialize the working directory
terraform init
# Generate and show an execution plan
terraform plan
# Apply the execution plan
terraform apply --auto-approve
# Destroy the resources
terraform destroy --auto-approve
The output looks reasonable and similar to the example code from before, and Codex even added comments to the code. Pretty impressive, right? You’ll also notice that because we didn’t specify any Stop sequences Codex kept generating content after finishing with the code we asked for, adding the Terraform CLI commands you may use to deploy this code. We’ll ignore that and focus on the Terraform code itself. Everything looks good until you get to the azurerm_kubernetes_cluster_node_pool resource, which looks reasonable at first glance. But if you review the azurerm_kubernetes_cluster_node_pool resource documentation, you’ll find the location, resource_group_name and cluster_name arguments don’t exist for this resource and the required kubernetes_cluster_id is missing. This Terraform code would not execute.
Give ChatGPT the same prompt to generate Terraform code, and it also generates invalid code:
resource "azurerm_resource_group" "example" {
name = "example-resources"
location = "West Europe"
}
resource "azurerm_kubernetes_cluster" "example" {
name = "example-aks1"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
service_principal {
client_id = azurerm_service_principal.example.application_id
client_secret = azurerm_service_principal.example.password
}
default_node_pool {
name = "default"
vm_size = "Standard_D2_v2"
node_count = 1
}
additional_node_pools {
name = "internal"
vm_size = "Standard_DS2_v2"
node_count = 1
}
}
resource "azurerm_service_principal" "example" {
name = "example-aks1"
}
resource "azurerm_role_assignment" "example_cluster_role" {
scope = azurerm_kubernetes_cluster.example.id
role_definition_name = "aksServicePrincipal"
principal_id = azurerm_service_principal.example.id
}
Overlooking the missing indentation, the code again looks reasonable at first glance. But try to run terraform validate on it, and you’ll run into a number of errors:
- The
azurerm_kubernetes_clusteris missingdns_prefixordns_prefix_private_cluster, where one of the two is required for the cluster - The
additional_node_poolsblock is not valid for theazurerm_kubernetes_clusterresource - The
azurerm_service_principalresource doesn’t exist
It’s clear that when it comes to Terraform, both Codex and ChatGPT struggle to generate valid code, likely due to the smaller training dataset for Terraform.
The Ugly: security vulnerabilities and production risks
The previous issues mentioned for OpenAI’s Codex when generating code could be considered an annoyance: while you may need to double check the code is valid, it can provide a useful scaffold to further work on the generated code. But there are some more serious concerns around Codex, and GitHub Copilot, which may give developers and companies pause. These include generating insecure code, generating code with known vulnerabilities or without latest security patches and copyright and license concerns.
Bugs in the training data can make it into generated code. In the original research paper introducing OpenAI’s Codex, researchers acknowledged safety concerns based on the training dataset which can result in the model generating known vulnerable code, stating, “Since publicly available programs have unknown intent and generated programs are often incorrect, executing these programs poses a security risk.” And a study from New York University researchers evaluating GitHub CoPilot (built on OpenAI’s Codex) found 40% of generated code in scenarios where vulnerability was possible was vulnerable to items found in MITRE’s “Top 25” Common Weakness Enumeration (CWE) list. When it comes to the cybersecurity landscape in particular, best practices change over time based on security findings and attacker techniques, while Codex’s dataset currently only extends up to June 2021. This also means recent security patches and updates to libraries and programming languages aren’t present in the training dataset, and thus won’t be included in code generated by Codex.
Consider also that many examples of Terraform code you’ll find on GitHub may not be secure. There are Terraform repos which are purposefully insecure, repos with Terraform resource examples which use default values and even repos which may contain obfuscated malicious code (for Terraform and other languages). The number of Terraform examples for AWS S3, DAX, EBS or ElasticSearch/OpenSearch which omit the encryption argument (i.e., encryption is default disabled) is staggering. The AI models have been trained on this data and don’t know what’s secure and insecure, and unless you explicitly detail in the prompt given to the AI that the resource must be encrypted, must be private, etc., then your resulting code may not be secure. And unless you read a Terraform resource’s documentation or a cloud provider’s best practices, you may not even know the generated code is insecure.
Let’s take a look back at the Terraform code generated in the previous section for an Azure Kubernetes cluster and focus on the azurerm_kubernetes_cluster resource. Because our input prompt didn’t ask for it explicitly, Codex omitted several important arguments which make the cluster insecure. Using a few Azure rules from the Policy Library for the Styra DAS Terraform System Type, we find the following policy guardrail violations:
- Private cluster disabled: Without
private_cluster_enabledset totrue, the cluster’s API is exposed to the public internet, unlessapi_server_access_profile.authorized_ip_rangesis also configured to restrict access to specific IP addresses (which it isn’t) - Network policy undefined: Without
network_profile.network_policydefined, you cannot ensure the principle of least privilege by securing ingress and egress traffic between pods - Cluster not encrypted with customer keys: Without
disk_encryption_set_iddefined, the cluster’s Nodes and Volumes are encrypted using Azure-managed keys, which provide less access control flexibility than customer-managed keys
And these results likely aren’t isolated to just Terraform. Using AI to generate your Kubernetes YAML, CloudFormation, Pulumi, Crossplane or any other infrastructure-related configuration files may lead to the same results. Which just makes it all that much more important to use a tool like OPA if you plan on using AI-generated infrastructure code, ensuring you have policy guardrails in place to identify these insecure infrastructure configurations.
Finally, there is the matter of copyright and licensing from the Codex training dataset. While all the code in the training dataset was public on GitHub, the dataset was not filtered to only permissive licenses like MIT and Apache 2.0. In fact, GitHub states in a June 2021 blog post that the Copilot (and thus Codex) training data included code licensed under GPL, other copyleft licenses and a variety of non-permissive licenses. Copyleft licenses require derivative works to be distributed under the same license terms as the original code and are frequently used to ensure open-source software and any modifications to it remain open source rather than contributing to proprietary, closed-source software. It’s for this very reason that Tabnine’s AI code generation tool was trained only on open-source code with permissive licenses. Since Codex does not provide insight into the source and associated licenses for generated code, there is no way for a user to determine if the generated code may be considered copyrighted. This has prompted some developers and projects, including the Free Software Conservancy, to move their repositories off of GitHub in protest. And in November 2022, a class-action lawsuit was filed against Microsoft, GitHub and OpenAI for violating copyrights of open-source code, which is still pending.
Under the law, however, it is possible that (and this is not a legal opinion) outputs from Codex and Copilot may be considered transformative work, in which case the use of public GitHub repositories for training AI models, regardless of software license, could fall under fair use. Where this argument could break down is when Codex and Copilot return copyrighted code in outputs verbatim. GitHub states in the Copilot FAQ that generated code contains training dataset code directly about 1% of the time. In fact, Copilot has even included copyright notices from code it was trained on in the generated code, reminiscent of the phantom artist signatures in AI-generated art. In response, GitHub built a Copilot filter which detects and suppresses suggestions containing matching training dataset code, however it is optional and up to the user to enable. In November 2022, GitHub further committed to releasing a Copilot feature in 2023 to additionally identify the repositories and their licenses from which matching training dataset code originated. These Copilot features are a step in the right direction to protect code authors’ rights, and hopefully they will be built into Codex itself in the future.
Concluding Thoughts and Recommendations
I’ll end this post with a word of caution: experiment wisely when using AI with your infrastructure configurations and do not directly deploy any generated code to production. In fact, GitHub makes this exact recommendation in the Copilot FAQs, where they state, “Like any other code, code suggested by GitHub Copilot should be carefully tested, reviewed, and vetted.” Some readers may think this is common sense, but the allure of AI-generated infrastructure code can blind some into making risky decisions.
Instead, consider these AI tools like a very junior engineer: they need very clearly-defined requirements to complete their work, their work should go through strict code reviews and testing and all infrastructure code (even that written by humans) should be tested against policy guardrails using a tool like OPA.
That’s also one of the key reasons that we created Styra DAS: to prevent any code or resource changes that violate a set of well-defined security and compliance guardrails from ever entering production across your infrastructure deployments. If you want to learn more about where or when (or if) you should use AI for infrastructure as code, or how policy guardrails can help secure your deployments, feel free to book some time with a Styra team member to explore our Kubernetes and Terraform policy guardrails. Our CloudFormation policy guardrails are currently in Beta and are available to enterprise customers.