Guarding the Guardrails — Introducing Regal the Rego linter
Two years ago, I explored the idea of linting Rego with Rego on this blog, and how we could use the abstract syntax tree (AST) representation of a Rego policy as JSON input data, allowing us to write a “linter” for Rego using Rego itself. Open Policy Agent (OPA) is well-established for use cases like application authorization, cloud infrastructure and Kubernetes admission control, where we normally talk about policy as guardrails. But who’s guarding the guardrails? Shouldn’t we have ways to ensure our policy code conforms to agreed upon rules? The premise of using Rego to lint Rego itself is that we’d be able to provide the same type of safety measures for Rego as we would for declarative data, i.e. writing policy on policy!
This was an interesting experiment, and while I saw a lot of promise in the idea, it was still a big step to go from experimental snippets and running “opa eval” to test the concept to something resembling a real linter. Additionally, a few limitations in our approach were identified. The first one was a blocker — the AST produced by OPA did not include the source location for many of the constructs. Having a linter telling you something you did was wrong without telling you where is of course not very useful. What’s more, as great as the “opa eval” command might be, it does not provide the UI one would expect of a real linter which normally would handle not just linting, but:
- Dealing with configuration options
- Formatting and other customizations
- Exit codes
- Creating summaries of violations
And many other details that together make for a good user experience tailored for the task.
The Rego Style Guide
While the idea of a real linter for Rego remained high on my wish list, I didn’t have the time to work more on that at the time, and other projects got prioritized higher. One of those projects was the Rego Style Guide. Having spent a considerable amount of time helping users learn OPA and Rego, I felt there was a place for documentation that wasn’t strictly just informational, but dared to be more opinionated.
While the OPA docs are great — I’ve learnt most of what I know about OPA and Rego from those — they by necessity cover all aspects of Rego, and do so without particular preferences to style or idioms. Sometimes though, rather than having someone say “here are all the ways you can do X”, I just want someone more knowledgeable than me to tell me “here’s the one way you should do X”. Having worked with OPA and Rego for years, I felt like perhaps I qualified as that knowledgeable person, and the Rego Style Guide came to be.
The style guide was well received, and while I had expected it to be useful for others, I was a little surprised to hear many saying they learnt a lot about Rego from that resource. That’s all great, of course, but it hadn’t really been something I had expected people to use a style guide for. A few others asked about the feasibility of turning some of the rules into Rego policy, so that the rules could be enforced programmatically. Sound familiar?
With the OPA docs providing good reference material, and tutorials for learning OPA, Rego or about specific use cases, the style guide providing a more opinionated view of the language, and of course hundreds of blogs, articles and other types of content available online, we have a pretty good “coverage” as far as documentation goes. Adding to that, the Styra Academy has long been a popular resource for learning OPA and Rego in a way that isn’t just about consuming docs. But perhaps there are more options to explore?
Where Docs Fall Short
Good documentation is essential for learning a new language or technology, and will likely be the most important resource in this process. There are many ways to consume docs, of course. Some developers spend a long time reading the docs before they open an editor while others try to hack away on something right away, referring to the docs only when needed. But documentation also comes with a few problems of its own:
- Knowing where to start. Unless you consume the docs in their entirety, and have an exceptional memory, you’ll most likely need to search the docs, and likely even frequently. The quality of search implementations vary widely across documentation platforms, but even if they’re good, you will need to know what to search for in the first place. This can be particularly challenging when faced with entirely new concepts, like Rego presents to many users (having its roots in Datalog and logic programming).
- Costly Context Switching. Consuming documentation requires you to frequently switch context, from coding to reading, and from reading to coding. Some handle this better than others, but combined with the problem of knowing what to search for, this can easily bring you out of the “zone” of productivity, and slow down the learning process.
- Is this up-to-date? Documentation for any active project is likely updated on a regular basis. As new features are introduced, and old ones are made deprecated or no longer idiomatic, it is often difficult to discern only from documentation what parts have been updated since your last visit, or what is currently considered idiomatic. This is particularly true for languages or technologies that you may not work with on a daily basis.
Ultimately, even great written documentation may not be for everyone. Some people simply prefer to learn through other mediums, like video based content, podcasts, or interactive tutorials.
Learning by Linting
While good documentation is essential, what other options do we have to help facilitate learning? Most probably think of linters as tools to help ensure a high level of code quality is maintained in a project, team or organization. Traditionally, the primary use case of linters have been to identify bugs, or otherwise problematic code, and suggest better approaches. These days, many linters extend this to also include more subjective rules, like good conventions for coding style. If we were to couple this with documentation that explains not just what could be considered problematic, but also expands on why that is, we’re looking at an excellent platform for teaching a language! Done right, a linter may help alleviate some of the problems we identified when using documentation alone:
- Automatically Search. Rather than having developers search the docs, linters do the “searching” in code looking for bugs, mistakes and style issues. The only thing left for the developer to do is to write code that contains bugs, mistakes or style issues — and most of us are doing that all the time already!
- One less context switch. Linters that provide references to documentation for any problem identified minimize the time spent switching context as only documentation relevant to the problem is presented.
- Evergreen Updates. Since linters are software packages, they’re easily kept up-to-date continuously using tools like package managers. This means that new rules may be added, existing ones updated, or possibly removed, as the language evolves and new features are introduced and new conventions or best practices are identified.
Combined with great documentation, we can see that linters could help fill some of the gaps of the “documentation only” approach to learning. Adding to that, they are of course also great for their original purpose of helping maintain a high standard of code quality, thus potentially adding value to both novice and experienced users alike.
Similar to how we can learn a great deal from having someone more knowledgeable review our code and offer tips, linters offer an automated way to continuously review code and detect issues. To truly enhance our learning experience, linters should go beyond simple error detection and provide a rationale for their rules, offering explanations for why certain patterns or styles are preferred or discouraged.
Introducing Regal
While I never really got the time to work on the linter I had envisioned, a few hours here and there in my spare time — and as a father of two, spare time is… limited — eventually turned into more hours, and at some point this side project of mine started to resemble something actually useful. Based on the principles outlined in this blog, and inspired by other great linters, like Hadolint for Docker files, and clj-kondo for Clojure, we finally have a linter for Rego: Regal!
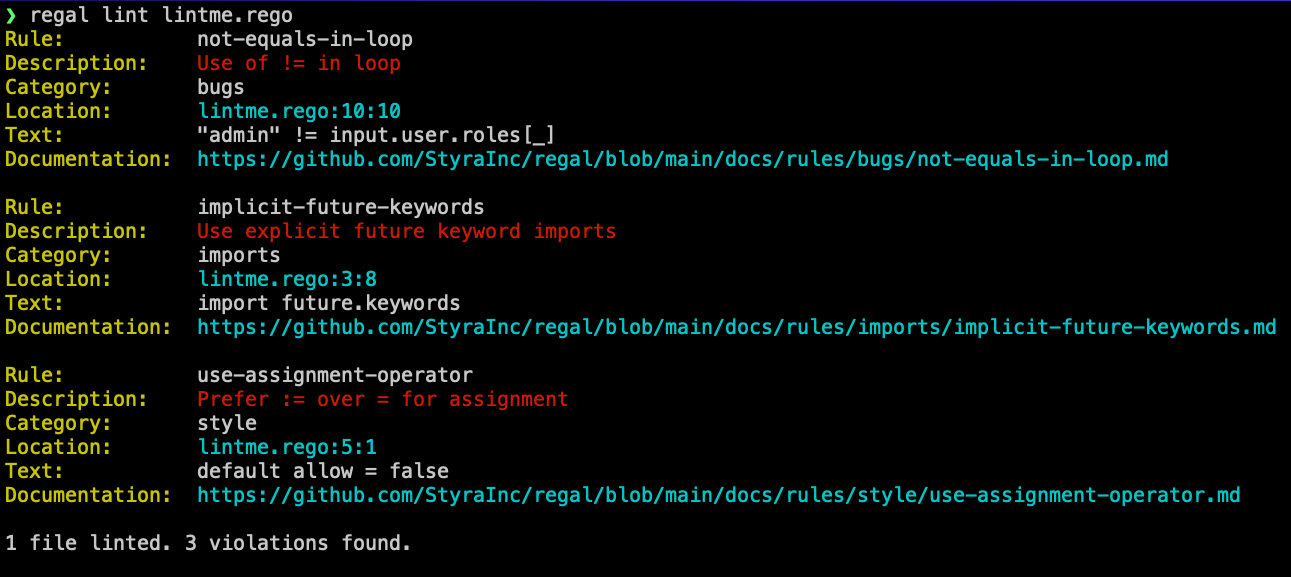
Example output from the Regal “lint” command
The goals of Regal are:
- To catch bugs, or probable bugs, in your Rego policy — guardrails around your guardrails!
- To help you become more proficient in the Rego language, by providing advice on good design, best practices, and idiomatic constructs.
- To help teams and organizations enforce their own best practices by making it easy to provide Regal with custom rules, written in Rego as any other policy.
Regal is a self-contained binary evaluating linter policy against the AST representation of Rego provided as input. Regal currently comes bundled with around thirty rules, with more coming soon. Each rule comes with extensive documentation, which is linked directly in the output of the “regal lint” command, allowing users to quickly learn more about potential bugs, style issues or suggestions on more idiomatic constructs. Additionally, some key features in the first release of Regal includes:
- Custom configuration, either via a config file (.regal/config.yaml) or CLI flags, to allow users to pick and choose which linter rules they feel are relevant to them. It is also possible to ignore a single violation directly in policy by providing ignore directives in a comment above the line containing the violation.
- Custom rules for those who want to extend Regal with their own rules to e.g. enforce things like naming conventions, or style guidelines in their team or organization.
- A few custom built-in functions added on top of OPA’s to help dealing with the Rego AST and improve the policy authoring experience for writing linter rules.
- Different output formats for linting where the report may either be presented as a table, a more compact format, or JSON for further processing by other tools.
- An option to write rules in Go, should Rego not suffice for some tasks. Currently, only the opa-fmt rule, which checks if a file has been formatted using the opa fmt command, leverages this capability.
Roadmap
With the first release of Regal published, we finally have a linter for Rego! While Regal already includes most of the features expected of a linter, there are always more opportunities to explore. Some of those on the roadmap currently include:
- More rules! For any common mistake, bug or non-idiomatic construct, Regal should have a rule to help guide users to the right path.
- A new custom category for rules, where no rules are enabled by default, but where users may provide configuration for common custom requirements, such as naming conventions, or allowed imports.
- Simplify custom rule authoring by providing a command for scaffolding — i.e. generating most of the boilerplate code needed for custom rules, and help verify that these rules are written correctly. In other words, help lint the linter rules!
- Provide more utility functions for custom rule authoring.
- A GitHub Action for Regal.
- A VS Code integration, and possibly integrations for other editors and tools.
Help Wanted!
Better than a roadmap though is feedback from actual users! The first feature request raised by a user was implemented the same day as it was created. While it’s hard to promise the same cadence for future issues, issues and feature requests based on real-world usage almost always trumps lofty roadmap goals, so if you’d like to help out, here’s some things you can do:
- Try it out! Download Regal, use it and provide feedback. Raise an issue or open a feature request. Any input is much appreciated!
- Suggest new rules for linting. If you find yourself repeatedly making a mistake in Rego and wish something would help you avoid that, let’s have Regal do that! But we’ll need to know about it.
- Spread the word! If you have friends or colleagues working with Rego, let them know about Regal.
- Star the project on GitHub.
Wrapping Up
A linter for Rego has been high on my wishlist for almost as long as I’ve worked with the language, and I know I’m not alone in this, as a linter has been one of the most upvoted issues in the OPA backlog for a long time. I’m really happy to be able to share Regal with this community, and I can’t wait to see how you use it. Thanks also to Stephan Renatus and Charlie Egan for ideas, code and reviews, which helped in finally getting Regal out to a wider audience.
If you’d like to learn more about Regal, or any other Styra project or product, join me and many others in the Styra Slack!