The Kubernetes Authorization Webhook
The webhook feature of the Kubernetes API offers a powerful mechanism to extend the modules that comprise the Kubernetes API servers with custom code for authentication, authorization and admission control. But while custom admission controllers have become the norm for building policy-powered guardrails around Kubernetes clusters, especially with projects like Open Policy Agent (OPA) Gatekeeper and commercial offerings like Styra Declarative Authorization Service (DAS), there’s surprisingly little information available on the Kubernetes authorization webhook. Why?
In order to answer this question, we’ll first need to understand how Kubernetes API handles authorization.
Note: While we will use OPA for authorization webhook decisions in this guide, most of the instructions here apply just as well to any authorization webhook. If you are planning to use something other than OPA or just want to learn more about Kubernetes authorization webhooks in general, this guide is still for you.
Kubernetes authorization
All state in Kubernetes is persisted in the key-value database etcd, and the job of the Kubernetes API server is primarily focused around two tasks— to control access to the data, and to control the shape of the data. The first task is performed by the authentication and the authorization module, while the second task is performed by the admission controller. A user request to change the state of the Kubernetes cluster must be approved by all modules in order for the request to succeed.
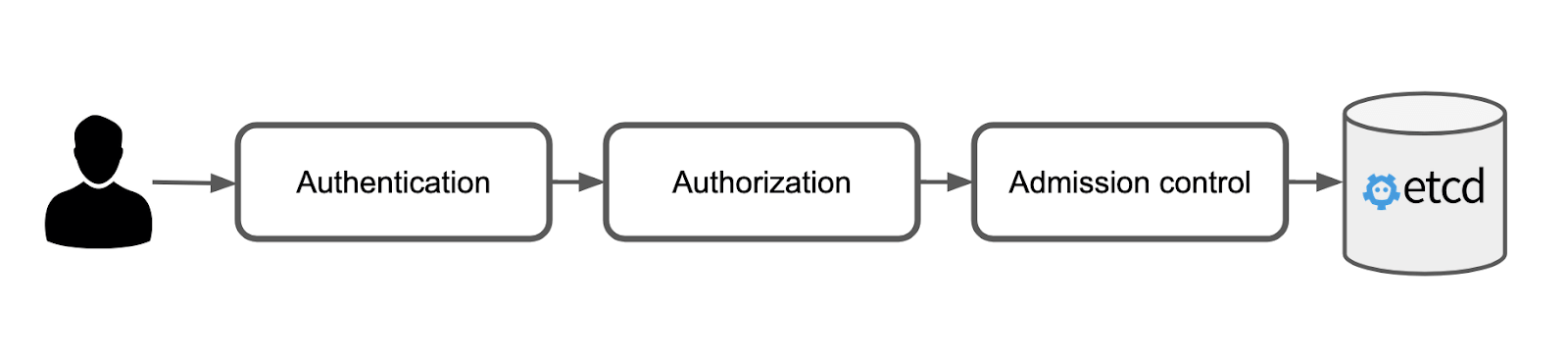
After the authentication module has established the identity of the user, the authorization module is consulted in order to determine whether the user is allowed to perform the request. The authorization module does this by asking all the authorizers configured to run inside of the module. This query, sent to each authorizer in the order they appear in the configuration, is called a SubjectAccessReview.
SubjectAccessReview
The SubjectAccessReview resource provided as input to each of the authorizers contains the data needed to authorize the request. Along with some very basic information about the user (username and groups) provided by the authentication module that preceded the authorization, it also contains a few details on the operation about to be performed and the resource on which the operation is requested.
In the example below, user “jane” asks the API server to list all pods in the “team-toucans” namespace.
Trivia: The Kubernetes API server by default sends SubjectAccessReview resources of version v1beta1. This version contains a typo in that the “groups” attribute is named “group” (in singular). This was fixed in the v1 version which you can use by providing the –authorization-webhook-version=v1 to the API server flags (see “Deployment” further down).
How would our authorizer respond to Jane’s request? We have three options—yes, no or maybe. While “maybe” (or perhaps more correctly, “I don’t know”) may seem like a weird thing for an authorizer to respond, it really means that, while the authorizer does not allow the request, it gives the next configured authorizer a chance to decide. If there are no more authorizers to consult, the authorization module will deny the request. Unless you have a really good reason not to—always respond with “I don’t know” to deny decisions. Crafting a SubjectAccessReview response is simple—all that is needed is to populate the status attribute with the decision, and on denied responses optionally a reason for the decision.
Example, allow response:
Example, “I don’t know” response:
Example, deny response:
Authorizers
With RBAC and an admission controller like OPA, you can start governing your Kubernetes clusters more effectively. However, because RBAC’s expressiveness is limited and admission controllers cannot enforce policies on read requests (they only see write requests), there are many common scenarios that will not be satisfied:
Users in the app-log-readers group should only be allowed reading logs from some pods in a given namespace.
Developers should be allowed read access to all namespaces, except kube-system.
Some users should be allowed admin access, but only when being on call.
Developers should be allowed access to any resources with a team name label matching the team the user is in.
Adding a webhook authorizer to the Kubernetes authorization module allows you to inject any custom logic as part of your authorization policy—including data from the Kubernetes API or external data sources. While you could write an application in any language to handle this, OPA provides not only a more convenient set of tools for dealing with policy decisions like this, but also one that has been battle tested in numerous production deployments.
A final note on authorizers—introducing a new authorizer like the webhook option does not mean throwing out your existing RBAC based policies and rules! In fact, relying on a webhook as your only authorizer in the authorization module makes for a pretty fragile configuration, since any problems in the webhook server could render the whole cluster unusable. A good practice is to delegate to RBAC what the RBAC authorizer does best (admin roles, namespace scoped policies, coarse grained access control) and only delegate to the authorizer webhook what the RBAC module cannot deal with.
Policy
Now that we know the shape of the SubjectAccessReview resources that will be provided to our webhook, we can start building our authorization policies. Using OPA and Rego, we can easily translate the scenarios not covered by RBAC into policy:
While somewhat contrived, the policy shows how we, with a relatively small amount of code, can craft powerful policies that take into account attributes like time, the state of Kubernetes or external data sources like user management systems. There are many ways of providing such data to OPA, and while covering all of them is out of scope for this blog post, Kubernetes data could be provided by a sidecar like kube-mgmt, or by simply query the Kubernetes API directly from within the policy.
With our authorization policy in place, we are now ready to make authorization decisions! But first we’ll need to deploy our webhook configuration to the Kubernetes API servers.
Deployment
While custom authorization webhooks might not be for everyone, the use cases listed above would probably have you think that it still seems like a fairly reasonable thing to reach for in many cluster configurations. So why aren’t there frameworks, products and ecosystems around webhook authorization the same way we see cropping up around custom admission control? The short answer: deployment.
Configuring a new validating admission controller webhook for Kubernetes is as easy as deploying a new ValidatingWebhookConfiguration resource. The Kubernetes authorization configuration is entirely static—meaning it can only be provided to the Kubernetes API servers when they start up, with no option to change the configuration at runtime. While certainly more complicated than deploying configuration with kubectl, it might not seem like that big of a deal. Restarting the static kube-apiserver pods however requires access to (at least parts of) the underlying system running Kubernetes, and this level of control is rarely provided in the many managed Kubernetes offerings. So unless you are running a self-managed Kubernetes cluster, you are out of luck. This alone leaves out such a big portion of the Kubernetes community that unless the major cloud providers change their policy to allow for configurable authorization,—or future versions of Kubernetes makes authorization webhook configuration more flexible— it is unlikely that we’ll see the same type of thriving ecosystems around custom Kubernetes authorizer modules as we’ve seen for admission control.
Configuration
Preparing the Kubernetes API servers for using an authorization webhook is a two step process. Firstly you’ll provide the required flags to the kube-apiserver containers, and next you’ll need to provide a configuration file for your webhook. The relevant flags would typically include something like below:
As can be seen here, we configure our webhook positioned after the RBAC module, meaning our webhook will only be consulted if RBAC denied the request (the RBAC module will always return the “I don’t know” response on denials, allowing other authorizers to be consulted). After that we point out the configuration file for our webhook. This file needs to be placed on the filesystem of the API servers, and might look something like this:
Starting the API servers we should now see our webhook beginning to receive SubjectAccessReview requests!
DNS
You might have noticed how we didn’t use an internal Kubernetes service URL (like https://opa.opa-namespace.svc.cluster.local) when setting up the webhook. This is due to the fact that since the API server starts before most other components in the cluster, including DNS services like CoreDNS, it can’t rely on those for resolving hostnames in the authorizer configuration. While you could of course run OPA outside of the cluster, there are also a few tricks you could try to run OPA inside of it:
Configure an Ingress controller to route external traffic. The Kubernetes API server authorizer webhook may then be pointed to the Ingress routed address of the OPA server.
Configure the OPA service to run with a static clusterIP, and have your API server configuration point directly to the IP address rather than a hostname. Since the webhook URL must use the HTTPS scheme, this doesn’t work well with most certificates given how they’re issued for hostnames rather than IP addresses. Self-issued certificates signed by the Kubernetes API server could be one way around this.
Modify the /etc/hosts file on the API servers resolving the clusterIP of the OPA service to the hostname matching the certificate.
Deploying OPA to the cluster is done through the usual means, but for minimal latency in the requests, it might be a good idea to let a daemonset deploy the OPA pods to the same master nodes as the API servers run on.
Try it out!
As we’ve seen, authorization webhooks can provide a powerful option for more fine grained access control than what the built-in RBAC module offers. Coupled with OPA, which makes authoring (and testing!) even advanced authorization policies quite easy, we can build an authorization system for Kubernetes that meets any requirements we may face. The complexity in getting everything configured correctly—not to mention just having access to a self-managed cluster in the first place—has however made the authorization webhook an option rarely seen in Kubernetes clusters. If your clusters meet the requirements for running one though, consider it as an option! Hopefully this guide has provided you the resources necessary to get started.
Oh, and one last thing—if configuring Kubernetes API server flags, building workarounds for odd DNS requirements and deploying OPA to a test cluster sounds a bit much just to play around with custom authorization webhooks, you can try running the Kubernetes authorization webhook using OPA example project from the OPA contrib repository, which will launch a local kind cluster on your machine configured with Kubernetes authorization webhooks using OPA running in the same cluster.
Learn more about Open Policy Agent and Kubernetes authorization here.