Centralized vs. Distributed Authorization: the CAP theorem
One of the best parts of working on the Open Policy Agent at Styra is that we get to help people design authorization systems for both their platform and their custom applications. The other day we were talking someone through the design tradeoffs of authorization for their application, and the first decision they had to make was whether they wanted a centralized authorization system or a distributed authorization system. Both OPA and Styra support either, so we have no real bias. We just get to help them choose the right architecture for their use case. In our conversation, it struck me that the core decision they had to make boils down to the CAP theorem.
Centralized versus distributed authorization architecture
If you’re not familiar, the CAP theorem says that whenever a network partition exists in a distributed system, that system cannot provide both availability and consistency. This applies to our discussion quite nicely.
In a centralized authorization system, you have a dedicated (micro-)service that makes all the authorization decisions (shown as Styra below). Any other service that needs an authorization decision makes a network request asking for a decision and then enforces that decision appropriately. This is the way authorization systems have been built for decades.
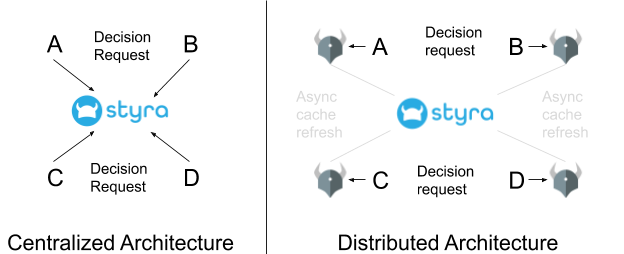
In the OPA/Styra distributed authorization system, you run OPA as a sidecar next to every software service that needs authorization decisions. OPA runs on the same server as (or even within the same process as) the software service in question. When the service needs an authorization decision, it asks OPA for that decision—that request is local to the server, requiring NO network communication. In order to do this, OPA periodically synchronizes with the centralized service (Styra in the diagram) so it has all the same information that the centralized service has, and therefore can provide the same answer that the centralized service would provide.
Tradeoffs via the CAP Theorem
The CAP theorem helps us understand the tradeoffs between the two architectures. Remember what the CAP theorem tells us: whenever a network partition exists in a distributed system, that system cannot provide both availability and consistency. To apply that theorem to the architectures above, imagine we have a partition between the node running service B and the rest of the nodes in the system.
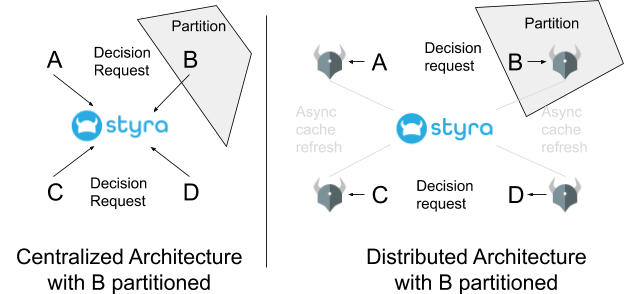
In the centralized architecture, when B is partitioned, B cannot retrieve any authorization decisions, i.e. authorization becomes unavailable. It must fail open (allowing every request) or closed (denying every request). For authorization, failing open is dangerous because a denial of service attack on the centralized authorization service, or even a simple internal network failure, would result in an attacker having complete access to the entire system. Failing closed means that service B drops every request on the floor and essentially becomes a brick. This often results in a cascade effect throughout a microservice architecture, since every client of B is getting every request denied, which in turn means that it denies every request it receives, and so on. On the upside, however, consistency is preserved because all authorization decisions are made by a centralized service.
For authorization in a distributed system, when B is partitioned, B still gets authorization decisions from a local store (in this case OPA), because that local sidecar runs on the same server (or for even better availability in the same OS process) as B. The partitioning does not impact B’s ability to get decisions at all; rather, the partitioning impacts OPAs ability to refresh its cache from Styra. When OPA cannot refresh its cache, the OPA running next to B may produce different decisions than the centralized service; hence, it gives up consistency but preserves availability.
Cloud-Native policy needs can change everything
Whether the centralized or distributed architecture is the right choice depends on the application and the authorization policies you want to enforce. To drive the point home, let’s compare an application built with say 10 components and a modernized version of that application built out of microservices with, say, 100 components. The end-user’s expectations for overall performance is the same for both applications, we’ll call it 1s response time. In the original application, a user request may have hit 2 services, whereas in the modernized application it might hit 5, 10, or even 20 services. Since the user’s expected response time is the same, the budget for each microservice API is somewhere between 2x-10x less for each microservice than for the original service. Moreover, because the budget for each API call is less, the network delay that constitutes a timeout and therefore a network partitioning drops substantially as well, making partitions more likely. The cost of an unavailable service increases as well because of the depth of dependencies among the microservices: if one of them becomes unavailable, they may all become unavailable.
In short, in a cloud-native/microservice application, there are many more microservices, necessitating stricter latency requirements, reduced tolerance of network delays, and therefore higher likelihood of partitioning. A distributed architecture for authorization becomes necessary because even a short network hop to a centralized service is often unacceptable (see the Netflix-OPA talk at Kubecon 2017 for more details).
From Interesting Theory to Harsh Reality
Working with many companies building authorization systems as part of a shift from monolithic to microservice architectures, we’ve seen more people feel the need to decouple authorization, and for that authorization to meet much stricter SLAs around availability and performance. Cloud-native architectures change the calculus for what “partition” and “unavailable” mean in practice, making it easy to see why most of our customers choose a distributed authorization system for maximum availability.
To lean more about decoupled authorization, book some time with a Styra team member today!
FAQ
What is the Cap Theorem in microservices?
The Cap Theorem in microservices refers to the idea that, when partitions exist in distributed systems, they are not able to provide both consistency and availability. This means that, for centralized vs. decentralized authorization architecture, there will be always tradeoffs in performance and availability. Authorization decisions that are made locally with OPA, as a microservice sidecar for instance, will have higher greater performance than a centralized system.