Enforcing Role-based Access Control (RBAC) Policies with OPA
A common use case our customers have for Open Policy Agent (OPA) is access control. The problem of access control is generally broken down into two parts, authentication and authorization. Authentication is about making sure we can trust someone’s stated identity, authorization is making decisions about who can do what. After users or workloads have a means of authenticating themselves, OPA steps in; as a general purpose policy engine, OPA is well suited to the authorization decision part of the access control problem.
Role-based Access Control (RBAC) has grown from a system design in the early 1990s into the loosely role-based patterns we see today. Tailscale’s excellent post ‘RBAC like it was meant to be’ covers this evolution in more detail. At a high level, RBAC is typically used to describe access control systems where subjects (users, workloads etc.) — often as members of groups — are granted access to perform operations on resources based on their granted permissions (roles & role bindings). For example, encoding requirements such as: “Only the HR team are permitted to update the document. Other employees may only read.” is trivial to implement in an RBAC system.
RBAC is everywhere, so much so that it’s hard to find a business or organization where users don’t interact with an RBAC system in some way. If you’ve granted your team viewer access on a document you’re writing; been automatically pinged for a code review because you’re a code owner; or been unable to update your own salary in the employee database chances are you’ve interacted with an RBAC system.
In 2023, the original RBAC design still makes for a great starting point when designing an access control system. With OPA now commonly taking up a central role in access control, we need a way to represent an RBAC system in OPA. Whether you’re migrating an existing RBAC system to OPA or building a new one from scratch, this post should provide you with some pointers to get started with implementing RBAC with OPA. If you’ve ever used Styra DAS Entitlements, some of these ideas ought to be familiar as we follow a similar model here.
RBAC From OPA’s Perspective
An authorization request in RBAC asks if a user can perform an action based on their permissions.
In the following example, Alice is trying to read the company’s Annual Leave Policy document (d0001). This represents what the authorization request sent to OPA would look like:
{
"subject": "alice@example.com",
"action": "read",
"resource": "d0001"
}To answer this query—i.e. for OPA to make an allow/deny decision—it needs data on subjects, roles, permissions and role bindings. Let’s see how we can represent the data needed to answer such queries in OPA. Starting with subjects, the actors in our system.
Subjects
Subjects are often human users. Information about human users from our identity provider might look something like this:
{
"users": [
{
"email": "alice@example.com",
"id": "u0001",
"name": "Alice"
}
]
}Typically user subject information used in an OPA RBAC system will come from another database or service such as Okta. One consideration is making sure that there is some way to link authentication subject data used in authorization requests with subject records. For example, the authentication system might provide a signed token containing the email address rather than the user’s ID.
Roles and Permissions
We know that Alice is interested in reading this document, however we currently have no data about permissions to determine if this is allowed. In an RBAC system, permissions are granted to roles so let’s create one of those first. Since roles are collections of related permissions we might find them represented like this:
{
"roles": [
{
"name": "d0001-reader",
"permissions": [
{
"action": "read",
"resource": "d0001"
}
]
}
]
}Similar to our list of subjects, role data is often sourced from another service. Making the mapping between your role datastore and OPA is homework.
With the information we have so far, we know the following:
- alice@example.com is trying to read resource
d0001 - The user with that email is, Alice and their user ID is
u0001 - We know there is a role which grants read access to
d0001
What we need now is some way of associating Alice with the role so that the request can be granted.
Groups and Role Bindings
Let’s imagine that d0001 is the company’s annual leave policy and that all employees can read this document. Let’s also imagine that we have another dataset at our disposal, a list of groups of employees and their members. While this likely comes from an external service or database again, the data is likely conceptually similar to this:
{
"groups": {
"all-employees": [
"u0001"
]
}
}
This simply defines that u0001, who we know to be Alice, is a member of the all-employees group.
Now all we need is a final piece of information. We need to know which users and groups have which permissions. We might represent this ‘role binding’ information in the following way:
{
"role_bindings": {
"all-employees": [
"d0001-reader"
]
}
}At last, we have all the data we need to make the decision. We know who wants to do what, what groups they’re in and what permissions they have on the resources in question. Now it’s time to think about what the OPA policy for such a decision might look like. This exercise will help us determine an efficient structure for the above raw data too. In an ideal world, we’d do a lookup based on the input data we have and provide the result.
The data we have is:
- Action
- Resource
So our ideal policy would be as simple as this:
default allow := false
allow if data.permissions[input.subject][input.action][input.resource]
This will deny all requests other than ones where we have a match for the input criteria. We’re missing something though, what is permissions? Permissions is the data that OPA is going to be using in our allow rule to make decisions. It’s our job to go from the raw data above into a structure like this which OPA can efficiently query.
{
"permissions": {
"alice@example.com": {
"read": {
"d0001": true
}
}
}
}In order to generate this, we’d need to do some processing in order to create a list of subjects and their permissions for each resource. You might also notice that the roles and groups are absent from the data in this format. We’ve used that raw data to create a simplified list of users and their permissions.
This data is best then loaded into OPA using the Bundle Service API. The documentation on this feature is worth reading as it’s one of OPA’s most powerful features. It has support for HTTP long polling to allow bundle updates to be pushed out and also supports partial updates via delta bundles expressed as JSON patches. The path to performant policies usually starts with well-structured data.
Once the data is loaded into OPA, and we POSTed the following request we’d see that Alice would be allowed access.
POST /v0/data/authz/allow HTTP/1.1
Content-Type: application/json
{
"subject": "alice@example.com",
"action": "read",
"resource": "d0001"
}You can try this for yourself in the Rego Playground.
Modeling Resource-level Permissions
So far we’ve not gone into detail about the resources in our system. We’ve created roles which grant access to them and we’ve granted said permissions to Alice but they’re still second-class citizens in our data. Since permissions can commonly be expressed as an action on some resource, it can be helpful to model permissions in this way — as being attached to resources.
‘Resources’’ are a generic construct, they might refer to something like a digital document, a physical lock or be something more conceptual. Whatever permissions you need to describe, thinking about subjects performing actions on resources can be helpful.
First, let’s imagine that we have some store that can provide us a list of resources, in our case documents:
{
"resources": [
{
"id": "d0001",
"name": "Annual Leave Policy",
"type": "legal_document"
}
]
}
This document has no permissions associated with it, so unless one of our existing roles has permissions for d0001, then it’s going to be inaccessible to everyone. Let’s imagine that the document permissions can be represented in the following way with some references to groups, users and actions.
{
"resources": [
{
"id": "d0001",
"name": "Annual Leave Policy",
"policy": {
"edit": ["u0002"],
"read": ["employees"]
},
"type": "legal_document"
}
]
}Here we are introducing a new way of defining permissions. When you’re generating permissions data for the policy to reference, you might need to merge this information with an existing list of role bindings and permissions from before.
We make reference to a new user here, u0002. This is the account of Bob who works in HR, with the addition of Bob, we have some new users and new groups:
{
"users": [
{
"email": "alice@example.com",
"id": "u0001",
"name": "Alice"
},
{
"email": "bob@example.com",
"id": "u0002",
"name": "Alice"
}
]
}
{
"groups": {
"all-employees": [
"u0001",
"u0002",
],
"hr": [
"u0002"
]
}
}With this new data, our permissions are going to look like this:
{
"permissions": {
"alice@example.com": {
"read": {
"d0001": true
}
},
"bob@example.com": {
"read": {
"d0001": true
},
"edit": {
"d0001": true
}
}
}
}As we can see, the data format hasn’t changed so we can use the same policy as before. You can test this out in the Rego Playground here.
It’s important to see here that RBAC is equally about the data and the policy. OPA is enforcing the policy in the context of the data. Getting the data to OPA is your job, but as mentioned above, there are some tools like OPA Data Bundles which can help a lot.
Rights for Robots: Supporting Machine Subjects
Commonly RBAC systems need to work with many different types of actors. So far we’ve assumed that all actors are users, this is often not the case. Imagine a system where a recurring batch job is updating a report. The batch job can update the report, but human users can read it. Let’s see how we might support that in our OPA RBAC system.
First, we need to know how to identify the batch job. Typically, batch jobs don’t have user accounts and operate with some workload identity within the environment it works in. Some examples of these identities might be:
- Kubernetes Service Account Token
- JWT from another OIDC token provider
- SPIFFE ID (used by Istio and others) e.g.
spiffe://prod.example.com/prod/batch-job - Identity from the host’s Trusted Platform Module (TPM)
Workload Identities are a complex space, but generally we have some known identity for each service which it can prove with a signed token or TLS challenge. We’ll use the SPIFFE ID as an example, but it could be any identifier.
Similar to our list of users, we’ll need to have a list of workloads for our RBAC system to use:
{
"workloads": [
{
"id": "spiffe://prod.example.com/prod/batch-job",
"name": "Report Batch Job"
}
]
}Ideally, we’d be able to specify the permissions like this on our resource too where the workload identifier is a first-class option in our permissions like users and groups.
{
"resources": [
{
"id": "d0002",
"name": "Generated Report",
"policy": {
"update": [
"spiffe://prod.example.com/prod/batch-job"
],
"read": [
"employees"
]
},
"type": "document"
},
...
]
}This would need to be translated into a permissions map which can support both human and machine subjects. The permissions map we want looks like this:
{
"permissions": {
"alice@example.com": {
"read": {
...
"d0002": true
}
},
"bob@example.com": {
"read": {
...
"d0002": true
}
},
"spiffe://prod.example.com/prod/batch-job": {
"update": {
"d0002": true
}
}
}
}Here we are starting to see how powerful the RBAC data model can be. It can be rendered into a flexible yet efficient nested structure from various raw datasets and used to make policy decisions.
Have a look at this Rego Playground to see how the permissions data has changed to support this.
Layering on ABAC
So far we’ve seen how requirements on an RBAC system can change the data we need to make decisions. Now it’s time to explore what might require us to change our policy code too. Oftentimes, additional requirements are needed above what can be offered by pure RBAC. Imagine that we have a policy of completing a two-factor authentication (2FA) prompt after accessing a resource from a new country. We can solve this problem with ABAC.
In such a domain, our requests into OPA might be extended to include new data like this:
{
"action": "read",
"resource": "d0001",
"subject": "alice@example.com",
"country": "france"
}
In order to make decisions, however, we need a list of users and their last 2FA country. This would be in addition to the permissions dataset we’ve been using so far in our RBAC examples and would likely be sourced from some user database before being synced to OPA. It makes sense to create this dataset with the same key provided by the authentication system, email address in our case.
Once we have that data, we also need to make some changes to our policy since just checking the RBAC permissions is no longer sufficient. Our old policy currently has no understanding of last_2fa_country:
allow if data.permissions[input.subject][input.action][input.resource]
If we’d loaded our list of users into OPA at data.users_by_email, then our new policy would look like this:
allow if {
data.permissions[input.subject][input.action][input.resource]
data.users_by_email[input.subject].last_2fa_country == input.country
}With this change in place, users not only need the permissions to perform the action, but also need to have most recently 2FA’d in the country they’re requesting from.
You can try out this ABAC extension to our example here.
Maintaining Decision Performance with Large Datasets in Large Environments
Throughout this post, we’ve seen how the demands on an access control system can change over time. We have shown how we can onboard more subjects, how to model permissions more effectively & how we can layer in ABAC controls on top of an RBAC system easily with OPA and Rego. While we’ve tried to go deep in places, these changing requirements and associated increases in data volumes aren’t uncommon in any large organization — access control quickly becomes a data-heavy problem. Think about all the data we’re considering using in our example domain:
- All users and their metadata
- All instances of all applications accessing data – services and jobs alike.
- Information about all resources where permissions are controlled
- An index of roles and their members
- Mappings from identifiers to subject and resource records
When working with large volumes of data like this in OPA, we must ensure that the data is structured efficiently for our policies and we encourage anyone on this journey to review the OPA performance documentation carefully. It is possible to compromise for example, we could use http.send to fetch data in Rego without needing to preload it into memory. However, this introduces latency from the network and response unmarshalling. It’s important to remember that OPA is performant largely for two reasons:
- It’s an agent and runs near its callers cutting out network latency
- It bases decisions on data loaded into memory
In a Zero Trust system where many application instances need to make fast authorization decisions at the same time, this deployment model comes into its own. The side effect though is that a lot of data needs to be replicated to many OPA instances in order to keep Policy Decision Points (PDP) local and fast. In addition, as explained in the OPA documentation, once JSON data is unmarshalled and loaded into memory it is around 20x larger. Even in a modest platform with only 100 nodes running workloads which need local OPA connections; a 100MB RBAC dataset incurs ongoing global memory use of around 200GB.
While there is often mileage in OPA for large data domains, in enterprise organizations, deployments of 20 times this size or more are not uncommon. In such cases, the cost of allocating gigabytes of memory to OPA on every node in your cluster can be prohibitively expensive. It is this use case we had in mind when designing Enterprise OPA.
Enterprise OPA is our enterprise-scale OPA distribution which uses a more memory efficient data representation. Let’s do some quick comparisons based on the benchmarking process in the Enterprise OPA documentation. The documentation’s example repo provides 5 bundles, each is named based on the volume of raw JSON RBAC data. Each bundle is an example dataset with an increasing number of users and roles.
When running the benchmark comparison for OPA and Enterprise OPA with each of the 5 example bundles of increasing size, we can see Load is able to process the same requests on an equivalent dataset while using much less memory.
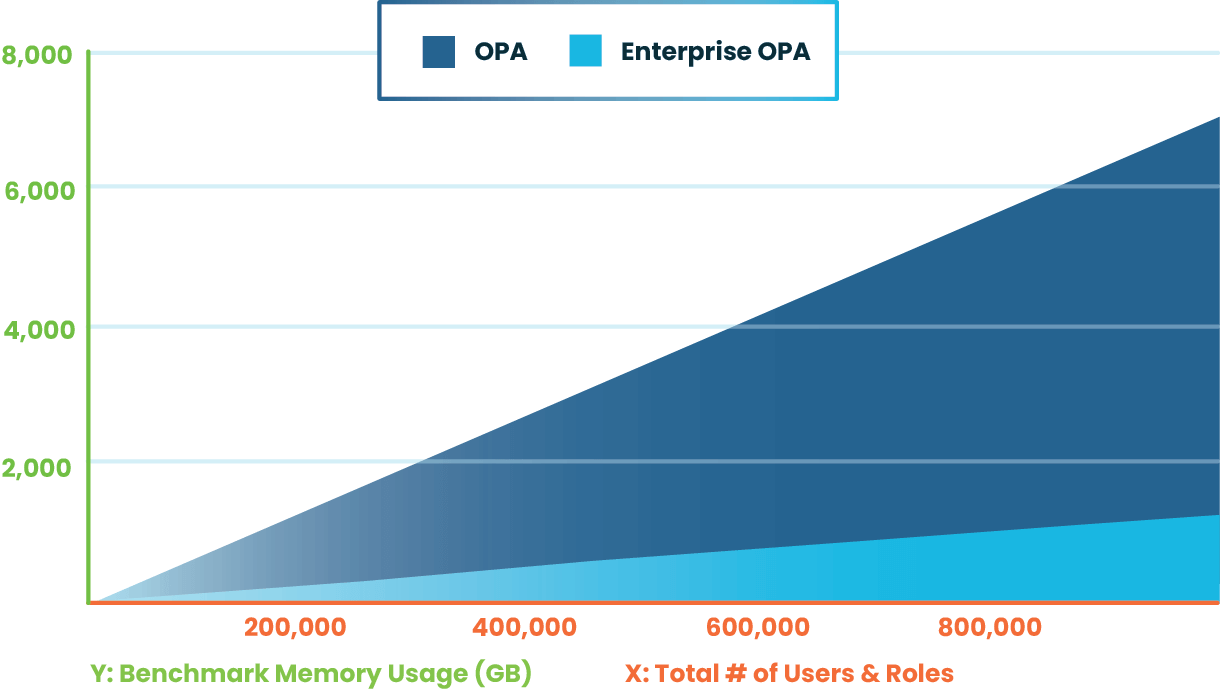
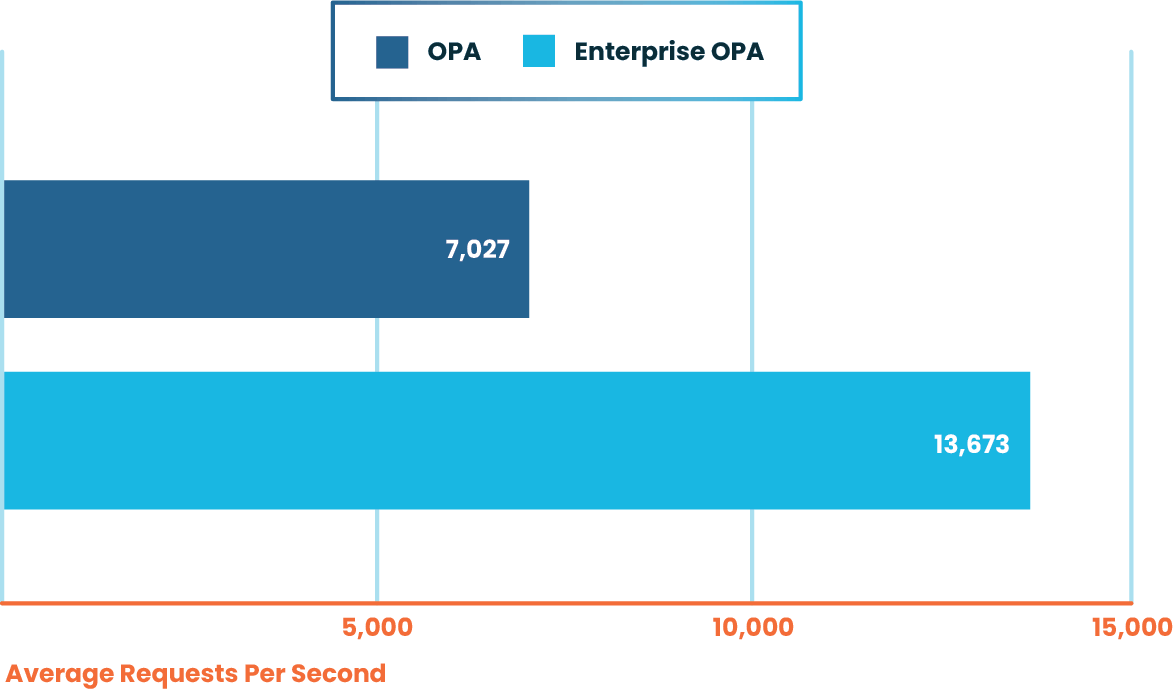
On top of that, Enterprise OPA achieves a greater rate of throughput too, achieving nearly double the requests per second.
Enterprise OPA is in Early Access and is available to try out today. If you’re working with large datasets in OPA (RBAC or otherwise), we’d encourage you to go over the performance testing documentation here and put Enterprise OPA through its paces with your own data. Please come hang out in the Styra Community Slack if you have any questions too!