When to Choose Enterprise OPA vs Open Source
Enterprise OPA is a drop-in enterprise edition of Open Policy Agent (OPA). Enterprise OPA solves several challenges large organizations encounter when using open source OPA. These include connecting to rich data sources, performance and memory usage when using large datasets, keeping authorization data up to date, and performing policy updates in a safe way. These are all technical challenges that start to manifest when the size of the data, the number of policies and the number of OPAs running become too large.
Enterprise OPA is designed to be a drop-in replacement for OPA. Every command and Rego language elements available in open source OPA is also available in Enterprise OPA and works in exactly the same way. Enterprise OPA then extends on these capabilities by adding additional features and performance enhancements.
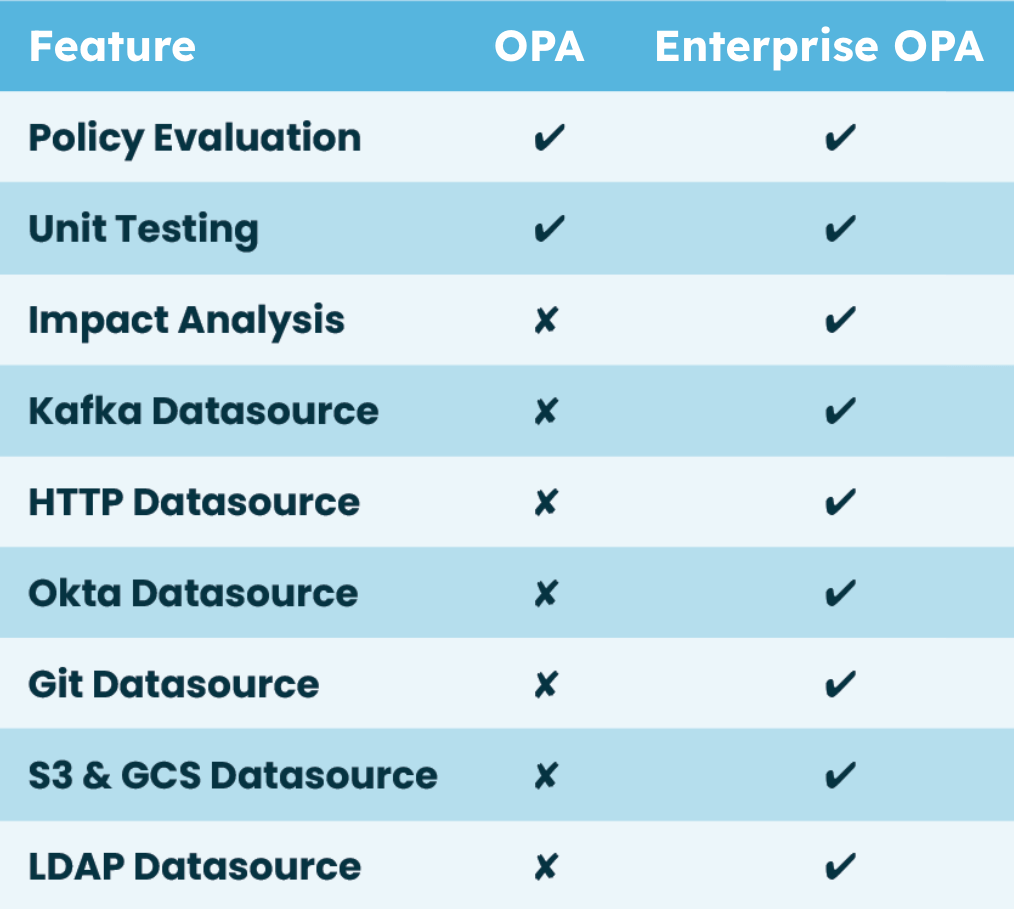
Feature Summary: Enterprise OPA vs Open Source OPA
Enterprise OPA has feature parity with open source OPA, making it easy to level up when you need an OPA alternative that is more robust. In addition to performance improvements, Enterprise OPA adds features that are important in enterprise environments.
Below is a summary of some key Enterprise OPA features. For a more in-depth comparison see this feature-by-feature chart camparing open source OPA and Enterprise OPA.
Live Impact Analysis
Replay previous decisions from the decision log against a new bundle before deploying it to see how much impact does the new bundle have on real-world decisions. Let’s say Enterprise OPA running with bundle version 1 would make an allowed decision for a certain input. Impact Analysis would rerun that same input but against bundle version 2 and compare the outputs to see if they match. If we do this for a large number of inputs we can determine how large an impact upgrading to bundle version 2 would have on our live system. Additionally, LIA reports changes in performance characteristics which can help catch any mistakes in your Rego that would lead to reduced performance during policy evaluation.
Data streaming from Kafka
You can connect Enterprise OPA to a Kafka topic to receive live data updates without the need for polling. This is the most efficient way to get up-to-date data to Enterprise OPA. Not only is the data in OPA always up to date, it also minimizes bandwidth usage by only transferring changes when they occur.
Pulling data sources
Enterprise OPA provides a number of data sources that it can automatically pull for data updates. This removes the need to package the data into the policy bundle but doesn’t come with all the disadvantages of “http.send”. A data source will not pause policy evaluation while the data is in transit, and it will not stop evaluation from working when it encounters a transient network error. The policy will just use the latest version of the data.
Memory Usage: Enterprise OPA vs Open Source OPA
A key feature of Enterprise OPA is that it uses a much more efficient memory model than OPA. This leads to dramatic improvements in memory and CPU usage when working with large data sets (>100 MB).
Let’s take a look at a common source of large datasets for enterprises: user role definitions and mappings. As an example, let’s see how much memory will a 379.5 MB JSON data file with a list of role definitions and role-to-user mappings take up in both OPA and Enterprise OPA. This is how the data is structured:
{
"roles": {
"role0": [
{
"action": "action869707",
"resource": "resource279303"
},
{
"action": "action183523",
"resource": "resource258803"
},
...
"users": {
"user0": [
"role179457",
"role428475",
],
"user1": [
"role448324"
],
"user10": [
"role471797",
"role138838",
"role395575",
"role371411",
"role470193"
],
...Let’s start open source OPA and see how much memory it will use when loading a bundle with this data. First, start OPA then run the curl command from another console.
$ opa run -s https://dl.styra.com/load/bundle-opa-400.tar.gz
$ curl 'http://localhost:8181/metrics/alloc_bytes?pretty=true'
3.0GBAs we can see, OPA is using 3.0 GB of memory to load our data – almost 8 times the size of the original JSON file. Let’s see how Enterprise OPA with handle the same:
$ eopa run -s https://dl.styra.com/load/bundle-opa-400.tar.gz
$ curl 'http://localhost:8181/metrics/alloc_bytes?pretty=true'
276.6MBEnterprise OPA is using 276.6 MB which is actually less than the JSON representation on disk and is a 10x improvement over OPA.
This difference in memory consumption becomes all the more important in production scenarios when the same policy is executed by many OPA instances. The charts below illustrate our measurements for memory footprint and CPU usage:
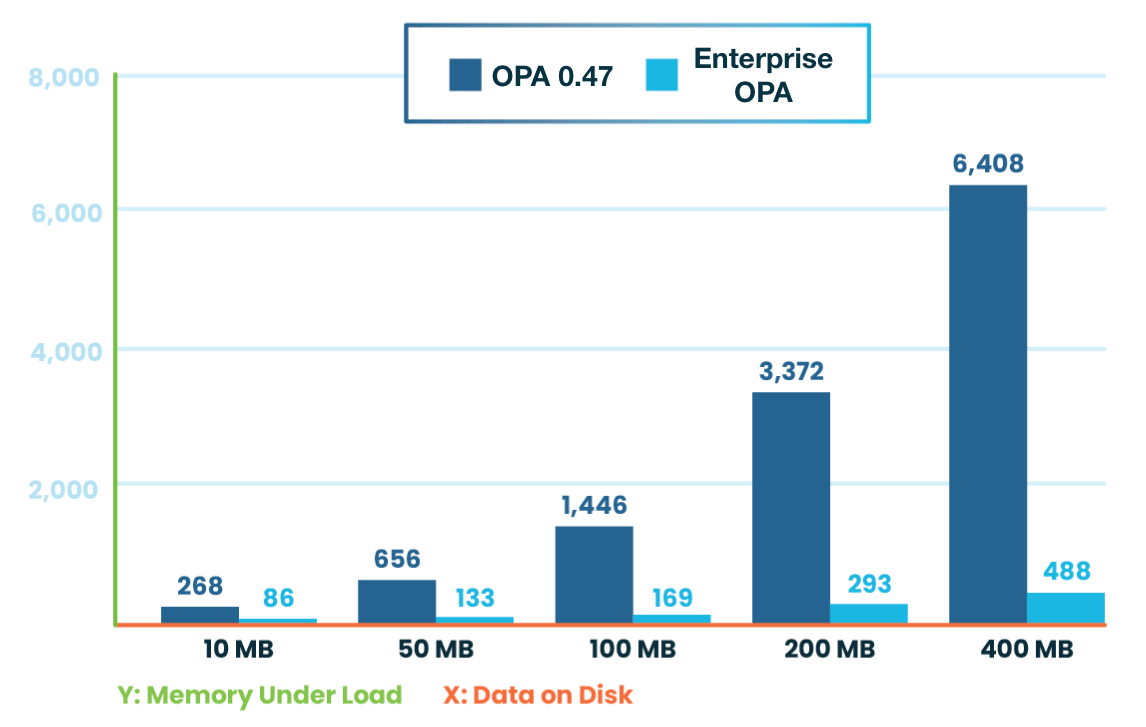
Memory Footprint (32 clients): Enterprise OPA uses 10x less memory
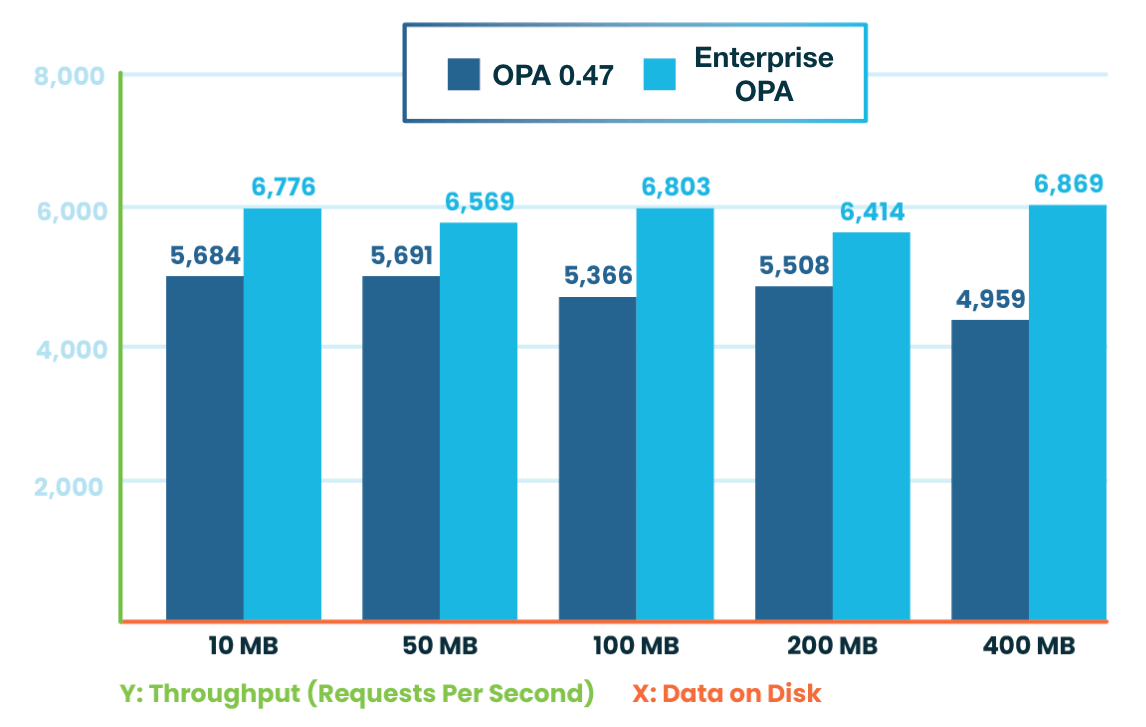
CPU Throughput (32 clients): Enterprise OPA supports 40% more
The second chart shows that Enterprise OPA outperforms OPA not only in memory footprint but also in CPU throughput. These savings translate into serious savings in cloud costs. Running 10 OPAs, this data set would cost about 275$ per month on AWS. Using Enterprise OPA can reduce this cost to about 43$ per month by allowing you to use much cheaper EC2 instances.
When to upgrade to Enterprise OPA
- When you need to integrate with external data sources.
- When your policy’s data set is hundreds of MBs and growing.
- When you are running more than 10 agents with the same bundle.
- When you need confidence that policy changes will perform as expected when deployed.
Conclusion
If any of the above conditions apply to you consider adopting Enterprise OPA to gain all the advantages of OPA with the additional enterprise feature set. Enterprise OPA will solve many of the thorniest challenges of OPA authorization without forcing a difficult upgrade process.
Request a demo and and see the Enterprise OPA difference yourself.