Securing AWS S3 Buckets with OPA and Object Lambda
TL;DR: AWS Object Lamba can authorize requests to S3. We can create an Object Lambda that calls Open Policy Agent (OPA) to get a policy decision. This delegation allows us to implement policies using Rego and manage them in Styra Declarative Authorization Service (DAS).
Amazon S3 supports defining fine-grained access policies for the objects stored in it. These policies work well in many scenarios but have limitations. For example, bucket policies are defined by a JSON-based configuration with a limited set of constraints that can be utilized. This doesn’t allow for defining policies based on user attributes not available in the request or the context. Writing complex policies in a JSON-based language is also cumbersome and difficult to maintain. Finally bucket policies are limited in size which can become a limiting factor for large organizations with lots of sensitive data stored in S3.
Using OPA for authorization can solve exactly these kinds of limitations. OPA can utilize external data to provide more context while Rego is a powerful language where the policy author can express general authorization rules that reduce the need for a long list of finer grained policies. Most importantly for complex environments OPA and Styra provide the facilities to manage, monitor and audit authorization policies at scale.
In this post I will demonstrate how OPA can be utilized as a PDP (Policy Decision Point) for Amazon S3 and show some example Rego policies. The two main components of these policies are:
- Authorization based on externally provided user attributes (geographical location)
- Authorization on the sub-object level — filtering rows in a CSV file served from S3
Extending S3 authorization with Object Lambda
AWS provides a very powerful extension mechanism for S3 in the form of Object Lambda. An Object Lambda is a Lambda function that will be called whenever a client tries to access an object in the S3 bucket. It has the ability to deny the request and also to modify the object before it is returned to the caller. To integrate OPA into the authorization flow we will create an Object Lambda that delegates the decision making to OPA. This way the Object Lambda will be our PEP (Policy Enforcement Point) while OPA will be the PDP (Policy Decision Point). I will of course be using Styra DAS to manage the policies and the user attribute data.
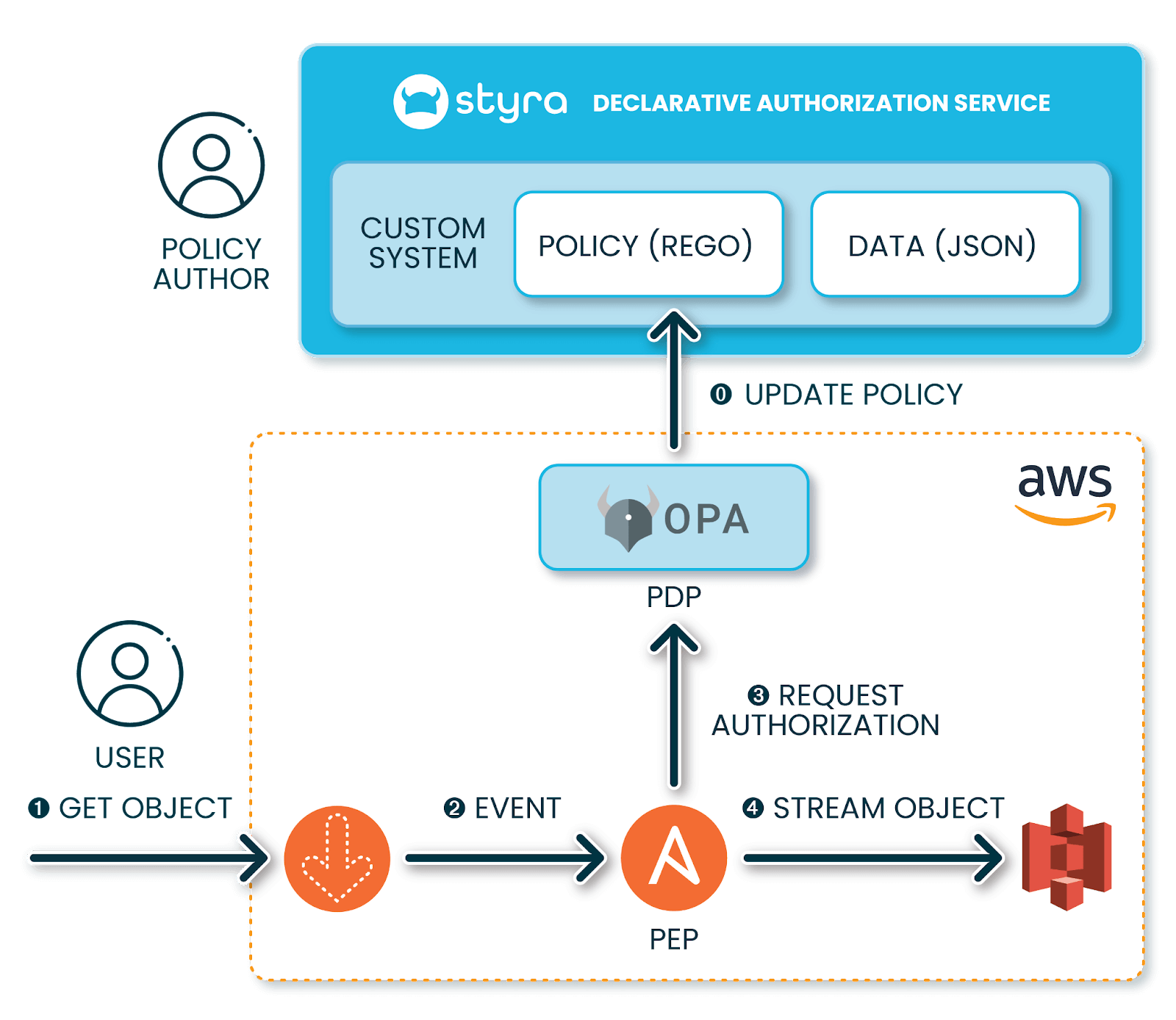
The Object Lambda will execute the following logic:
- Assemble a policy decision request to OPA with all the information about the S3 get request.
- If the response from OPA is to deny the request, reply to the caller with an HTTP denied response.
- If the OPA response is allowed, check the returned data_permissions object for a list of allowed data rows.
- Fetch and parse the requested CSV file from S3 and filter the rows based on the data_permissions results.
- Return the filtered S3 object to the caller.
The input sent by the Lambda function to OPA:
{
"function_name": "s3-authz-demo-LambdaFunction-a5Frk2nneVRY",
"userIdentity": {
"accessKeyId": "AKIA2TCOXLGWRQYUDS7M",
"accountId": "728162064813",
"arn": "arn:aws:iam::728162064813:user/adam-aws-cli-user",
"principalId": "AIDA2TCOXLGW425ZR6MBY",
"type": "IAMUser"
},
"user_request": {
"headers": {
"Accept-Encoding": "identity",
"Host": "s3-authz-demo-olap-728162064813.s3-object-lambda.us-east-1.amazonaws.com",
"X-Amz-Content-SHA256": "e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855"
},
"url": "https://s3-authz-demo-olap-728162064813.s3-object-lambda.us-east-1.amazonaws.com/prefix1/data1.csv"
}
}
To which OPA will reply:
{
"allow": true,
"data_permissions": [
"public"
],
"deny": [],
"object_path": [
"s3-authz-demo-olap-728162064813.s3-object-lambda.us-east-1.amazonaws.com",
"prefix1",
"data1.csv"
]
}
Or in case of a deny decision:
{
"allow": false,
"data_permissions": [
"public"
],
"deny": [
"Missing prefix"
],
"object_path": [
"s3-authz-demo-olap-728162064813.s3-object-lambda.us-east-1.amazonaws.com",
"data1.csv"
]
}
This is how the CSV file looks like in S3:
| ID | Classification | Data |
| 1 | public | 32rp98hp4qihfelrgjnp4938ghperoiksjdgnsfdlkg09 |
| 2 | public | r43[209fjo[4ni[gdflkgldfkgjsfldgk]]] |
| 3 | sensitive | fdsagi[8ehgeihgnlfsdkjvlsdfkjhblksfdhgiosurghe4] |
The same file after the Lambda function filters it based on the OPA response (data_permissions only allows ‘public’ records):
| ID | Classification | Data |
| 1 | public | 32rp98hp4qihfelrgjnp4938ghperoiksjdgnsfdlkg09 |
| 2 | public | r43[209fjo[4ni[gdflkgldfkgjsfldgk]]] |
Finally, let’s take a look at the Rego policy that makes the decisions:
package rules
import data.userdata as users
default allow = false
allow {
count(deny) == 0
}
deny["prefix1 data can only be accessed from the US"] {
user.region != "US"
object_path[1] == "prefix1"
}
deny["prefix2 data can only be accessed from outside the US"] {
user.region == "US"
object_path[1] == "prefix2"
}
deny["Missing prefix"] {
count(object_path) == 2
}
deny["Unknown Object"] {
not object_path
}
data_permissions["public"]
data_permissions["sensitive"] {
user.security_clearance > 2
}
user := users[replace(input.userIdentity.arn, "/", "_")]
object_path := regex.split("/", regex.split("://", input.user_request.url)[1])
The policy uses two user attributes: region and security_clearance. Region determines if the user can access objects under certain prefixes, while security_clearance determines which types of records the user has access to.
These attributes come from a data source that needs to be loaded into OPA along with the policy. This is accomplished by creating a policy bundle which is basically a zip file with the policy and the data. Styra DAS is a convenient platform for managing both the policy and data while keeping all OPAs up to date.
Of course for this to work the Object Lambda has to be implemented. I used Java code to do this (see link to repo below) but any other language supported by Lambda can be used for this purpose. The only requirement is that you can make HTTP calls to OPA for the policy decision request or in case of writing the Lambda in Golang OPA can be embedded as a library.
Also note that the CSV file parsing is just an example of what can be achieved. Very different scenarios (e.g. modifying photos, redacting documents, etc) can be achieved with the right set of policies and Object Lambda logic.
Flexible AuthZ with OPA and Rego
By implementing an Object Lambda to be our PEP we can use OPA and Rego to provide flexible and extensible authorization policy to S3 objects. This can provide many benefits to organizations relying on S3 and having access control requirements that can be well defined in Policy Based Access Control (PBAC). Even better if the organization is already using OPA for other authorization use-cases and can now manage S3 object-related policies in the same way.
Code repo
All the code and much of the infrastructure setup can be found in my Git repository including a guide to set everything up so you can test it yourself.
Want to see how this approach works in action? Be sure to sign up for a Styra DAS demo and explore the many ways you can implement policy as code.