Entitlements: Architecting Authorization
By its general purpose nature, Open Policy Agent (OPA) allows for a unified way of dealing with policy across a wide range of use cases. One particularly interesting use case for OPA, and one which will be the focus of this series of blogs, is that of application authorization (or entitlements, or simply, authorization). In the first part, we’ll look at authorization from an organizational and architectural point of view, and in the next part we’ll zoom in on the details of implementing authorization, including strategies for working with authorization policy and data at scale.
What is authorization?
Merriam-Webster defines the act of authorizing as “to endorse, empower, justify, or permit by or as if by some recognized or proper authority.” Put simply, our goal is not only to keep the people out (which is often the focus when authorization is discussed), but just as much to permit, or even empower, the users of our systems to be as efficient and productive as they possibly can be! If you ever worked in an organization where you commonly found yourself asking (and worse, waiting!) for permission to do something required to solve the tasks you were assigned, you probably know all too well how demotivating and draining that experience could be. How would we best work to avoid this?
A common principle of agile software development is to start with identifying the stakeholders involved, and to keep those involved in the process of the development. If we were to identify the stakeholders of an authorization system, who would those be? And how would an authorization system differ from other types of systems where we commonly see policy as code applied?
Stakeholders
First, the organizational scope of authorization policy is much wider than policy focused on a particular domain, like infrastructure or Kubernetes admission control. While policy as code allows for transparency and outside contributions to the policy process, it is still likely to be the case that the major part of e.g. infrastructure policy is decided by a dedicated ops or infra team, or that the policies governing Kubernetes admission control are mainly worked on by the “Kubernetes team,” and so on. Application authorization on the other hand, is of interest to pretty much all development teams in an organization, and the details of the authorization policy deployed are likely to be not just important, but subject to review, discussion and criticism from a large number of stakeholders.
Secondly, and on the topic of stakeholders—most authorization systems will have users! Users that knowingly or unknowingly interact with the authorization system, possibly daily. Authorization as such can’t be considered as simply an internal concern, or one optimized purely for developer experience, but should be thought of as an important component contributing to the overall experience of using the system. Simply put, the end-user experience will need to be put in the forefront when designing a system for authorization, and failure to do so is likely to have negative consequences for the product or service as a whole.
A third stakeholder is the group of people who will maintain or administer the system over the course of its lifetime. This includes things like making sure the right people belong to the right groups, or have been assigned the appropriate roles required for them to do what they need from the system, having onboarding and offboarding procedures in place, or to make changes as employees change departments, or users upgrade their account subscription. This group is interesting, as it often includes people far away from the development process, and as such often neglected when designing authorization. This group commonly included human resource personnel for internal authorization systems, or even end-users managing permissions via self-service.
When building an authorization system, we need to keep all stakeholders in mind, and ensure that the system caters to the needs of both developers, administrators and end-users! With that, we’re ready to take a look at the technical aspects of authorization. What are some of the components that commonly comprise an authorization system?
Designing authorization
Luckily, we’re not the first ones to consider authorization from a larger perspective. Just at the start of the millennium, the first XACML standard was published. XACML stands for “eXtensible Access Control Markup Language,” and despite its name, the standard describes not just a markup language for policy, but an entire architecture for working with policy. While the verbose, XML-based (naturally, everything was XML at the time!) policy language hasn’t aged well, the architecture around authorization described by the XACML standard is largely—and perhaps, surprisingly—still relevant. The XACML architecture split the responsibilities of authorization into several distinct components, and while the terminology (and associated abbreviations) used to describe these components abused to letter “P” to an almost comical extent, the principles still form the basis of how authorization systems commonly are designed to this day. Quite impressive! Which are these components involved in the XACML architecture, and how would something like OPA fit in, had we dropped it on top of it?
Policy Administration Point (PAP) and Policy Retrieval Point (PRP) – Where policy is administered, respectively stored. In modern, cloud-native colored terminology, these responsibilities would typically belong to what we’d call a control plane—Styra Declarative Authorization Service (DAS) of course being the control plane of choice for OPA.
Policy Decision Point (PDP) – where policy decisions are made. This would be OPA.
Policy Enforcement Point (PEP) – where policy decisions are enforced. When OPA is used for authorization, this would be the client application asking OPA for a decision, and then acting on that decision (for example, by returning a 403 Forbidden response to the caller).
Policy Information Point (PIP) – A service that provides the PDP with additional data it might need to make informed decisions. While OPA provides the ability to reach out to a “PIP” via the http.send built-in function, the distributed nature of modem systems generally favors provisioning data asynchronously via the same distribution channel (i.e. the control plane) as the policies.
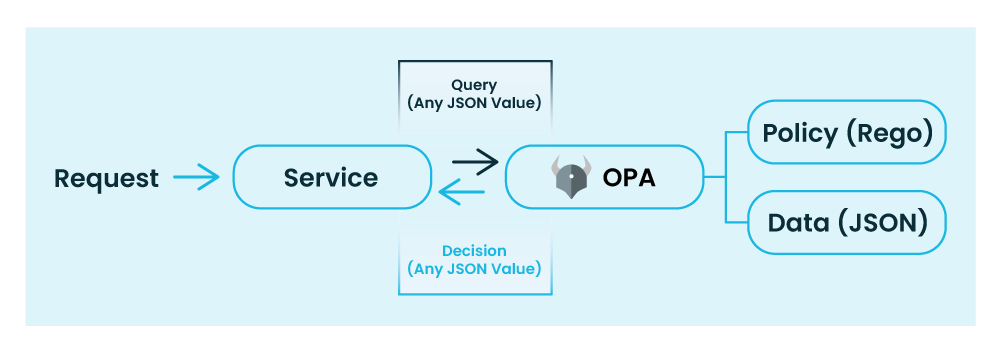
The XACML architecture vs. the OPA policy decision model
Looks pretty familiar, right? The big change in architecture since that time doesn’t revolve around what each of the components are doing, but the distribution of the components, and in extension to that, the sheer number of components in modern microservice deployments. Since most, or even all, components of the monolithic application would be running in the same container (or application server) and on the same host, a single policy engine (or “PDP”) could service all requests for the application, and fetching extra data at policy evaluation time (via the “PIP”) wasn’t too costly, given only a single extra request added to the total latency budget.
With applications now split up into hundreds, sometimes thousands of services, having a single “policy decision point” would negate the benefits of the distributed architecture, like scalability, and resilience. Additionally, the latency overhead of having each service reach out to an external component on a different host, or even network, would quickly become prohibitively expensive. One way of solving this problem in a distributed manner is to treat the system responsible for policy decisions like any other distributed component, and deploy these components alongside each service in the system, effectively providing a private policy engine per component deployed. This naturally entails that a modern, distributed policy engine like OPA will be distributed in hundreds or even thousands of units. To quote a friend who spent many years working for a XACML vendor: “there are likely more deployments of OPA inside some of the larger organizations than there are XACML PDP’s in the entire world.” Quite an interesting development!
While the distributed architecture brings many benefits, it doesn’t come without challenges of its own. Even with decision engines deployed as close to the services as possible, the latency overhead of reaching out to external applications could still pose a problem, and different performance models might need to be evaluated.
Data considerations
With the components of an architecture for authorization mapped out, we may proceed to zoom in a bit on the details. The “PDP,” which in a modern solution would be OPA, commonly requires two things in order to make policy decisions—policy and data. While we’ll take a closer look at the details of policy in the next part of this blog series, how data is dealt with often has a bigger impact on the architecture around authorization. How so?
Application authorization policies differ from most other types of policy in that the domain—i.e. the data, provided to your authorization policy—is typically not decided by an external system that you don’t control. When you write policies for Kubernetes Admission control, the data is provided to you by the Kubernetes API server. Infrastructure policies using Terraform? Provided by the Terraform tooling. Kafka authorization? Provided by the Kafka broker… and so on. So, who provides the input data when your service wants to delegate authorization to OPA? Well, you do! Designing authorization puts us in a situation where we are responsible for not just the design of the authorization policy, but where we’re just as much responsible for providing our policy with whatever data is necessary in order to make informed policy decisions. This poses both challenges and opportunities for a development organization looking to implement authorization at scale.
Authorization data design
Whatever data is necessary for application A isn’t necessarily the same as the data required for service B, which might differ somewhat from the requirements of service C, and so on. Add to that the fact that each service may be owned by different teams and you’ll easily end up in a situation where each team writes their own policies, taking into account only the data needed for their specific service, with little or no reuse between services or across team boundaries. While this might be fine from a pure technical point of view—after all, why should you provide your service something that it likely won’t need?—dealing with different input data in each service likely means the policies to deal with that data will differ just as much. While I think most of us like the idea of autonomous teams, collaboration often proves to be beneficial, and a somewhat standardized format for authorization decision inputs and outputs is likely to be desirable. Some concerns addressed by unifying the data format for authorization decisions include (but is certainly not limited to):
Compliance. Organizational requirements, as well as laws like the GDPR, may impose restrictions that must be enforced consistently across all services.
Auditability. Being able to easily monitor decisions taken is one of the most important aspects of any authorization system. The more unified the authorization system is, the easier it will be to track deviations from the norm.
Maintainability – Having an agreed upon format for input data, as well as common policies, will ease the maintenance burden over time, as well as making it much easier to deploy required updates to authorization policies across a large fleet of services.
Don’t be intimidated to think that a unified way of dealing with authorization won’t leave much room for creativity. A common approach seen in many successful large-scale deployments is a hybrid approach, where common concerns are identified and dealt with “centrally”, by e.g. a security or an architect team, and where responsibilities of individual services are left to the owner of those services once the common policy checks have been completed. Important to note is also the fact that we’re dealing with policy as code—not PDF documents or Confluence pages—so even common organizational policy crafted by a “centralized” unit like a security team should be transparent to anyone in the organization.
Data distribution
While the structure of the data provided for policy decisions has an impact on both performance and organizational concerns like cross-team collaboration, the distributed nature of many modern systems brings an entirely different class of problems, namely how to best distribute the data needed for policy decisions when working with hundreds or thousands of decision points.
A traditional approach to data distribution entails pushing the data only to the outer edge of the system, where a component like an API gateway would use the data to make authorization decisions on requests as they entered the system, and any request that made it past the gateway would be considered “approved” by that component, and as such not subject to further authorization checks. While simple from a data distribution perspective, this model however comes with several problems. With authorization being enforced at only a single point in the system, it naturally entails that anyone that manages to make it past that point has pretty much unlimited access to the systems behind the gateway. Another problem is that you’ll likely want your internal systems (i.e. those inside of the Gateway) to be subject to authorization policy, and having them route their requests via the Gateway isn’t ideal, not to mention difficult to enforce.
These problems are largely addressed by the zero trust security model, where any request through a system needs to be verified in every component it passes, and no assumptions are made based on the origin or the contents of the request. Rather than verifying permissions at the edge of the system, authorization checks are now performed everywhere. While this addresses the security concerns around the centralized model, it naturally means that any data needed for authorization also needs to be everywhere. Since we’d ideally find any required data in memory (as opposed to having to reach out to an external service) at the time of a policy decision, relevant data needs to be distributed before the decision is made. Working with large datasets, this quickly becomes expensive, and strategies for dealing with that is commonly a big focus of the architecture around distributed authorization. Some common strategies include:
Sharding and partitioning – Different services likely protect different resources, and only for actual users of that service. When architecting data distribution for authorization, identifying what data is needed by any particular service and distributing only data of relevance becomes a key consideration.
Partial evaluation – Even without all data available at policy evaluation time, an authorization service may still provide a response detailing the parts that it does know about, and let the client deal with the unknown parts, for example by fetching data from a distributed cache, or a relational database.
Fetching data – While data is ideally available before a policy decision is required, it isn’t always a viable strategy. The sheer volume of data might be too big for a single service, let alone multiple services, to keep in memory, or the data might update so frequently that the data mirrored in memory is likely to be out of date.
Caching – While it’s sometimes necessary to reach out to an external service for data, it is imperative that it’s only done when absolutely needed. Caching data helps keep the total latency budget in check by only doing lookups when the same data hasn’t previously been retrieved. Sometimes it might even make sense to have the client cache the authorization decisions themselves, as asking the same question twice likely results in the same answer.
Finally, another complicating factor in authorization systems is that they almost always will need to deal with existing (i.e. “legacy”) components for user management and permissions. Few organizations set out to build identity or authorization systems entirely from scratch, but rather see these evolve over time. Integrating with systems that were built with no notion of distributed authorization in mind is commonly one of the big challenges in large scale deployments.
Wrapping up
As we’ve seen by now, architecting authorization requires careful consideration not just around our technology stack, but just as much around organizational matters, data design and challenges in distributed architectures. While there’s no shortage of challenges, the impact of a well designed authorization system, and the number of stakeholders involved, also makes it an interesting—and potentially rewarding—problem to work on!
To summarize:
Consider the stakeholders of your authorization system, and how they will interact with it. Make sure to keep them involved in the development of your authorization system!
Know the key components in your distributed authorization and the role they play in the overall architecture. Identify challenges in distributed, zero trust, environments and how to best tackle those.
Design the contents and structure of the data required for authorization. Optimize for collaboration across teams and components.
Learn about the challenges of distributing authorization data across hundreds of services. Consider the best strategies for your requirements.
In the next part of the series, we’ll take a closer look at the decision point component (i.e OPA!), integration with user management systems, the structure and design of authorization policy, and how we can leverage OPA to solve many of the challenges presented in distributed architectures.
Watch this webinar to learn how your organization can decouple rules, regulations, and policies from an application and leverage existing data sources with Styra DAS for Cloud-Native Entitlements.