Zero Trust with Envoy, SPIRE and Open Policy Agent (OPA)
Enterprises have traditionally relied on perimeter network security to keep attackers out and protect their organizationally unique sensitive data and resources. This approach works on the principle “verify, always trust” wherein authenticated users inside the network are trusted by default and allowed unfettered access. With the shift to cloud-native architecture, perimeter-based defenses have become obsolete and leave systems inherently vulnerable to malicious actors. For example, legacy enterprise systems have become much more complex and consist of connected devices (IT, IoT, IoMT, OT, etc.), infrastructure components, and software-as-a-service (SaaS) applications distributed across various data centers, to name a few. Employees and customers are increasingly accessing these devices and systems remotely from home, distributed offices, cafes and not just from self-hosted networks. Traditional security models are no longer enough to deal with today’s distributed computing environments as the network location does not dictate the security of a resource. Even if you assume allowing trusted users unlimited access to internal resources like compute is a good idea, how do you protect from system misconfigurations bringing down your entire Kubernetes cluster or rogue actors accessing all your applications? It’s likely that many organizations will adopt a hybrid approach and leverage network segmentation to place resources behind a unique network protected by a gateway. Even with this approach, it’s essential that such gateway components are flexible enough to adapt to threats and dynamic client requests.
What are Zero Trust Architecture principles?
To address the complex requirements of today’s enterprise infrastructure, Zero Trust Architecture was conceptualized:
As the name suggests, the main idea behind Zero Trust is to “never trust, always verify”. Zero Trust assumes there is no implicit trust granted to assets (devices, applications, etc.) or user accounts based solely on their physical or network location. In other words, the model assumes that the attacker is already present in the environment. The Zero Trust Architecture attempts to protect data and prevent unhindered lateral movement by explicitly authenticating and authorizing both users and devices before each resource access.
The basic tenets of Zero Trust Architecture as defined by NIST 800-207 are:
- All data sources and computing services are considered resources.
- All communication is secured regardless of network location.
- Access to individual enterprise resources is granted on a per-session basis.
- Access to resources is determined by dynamic policy—including the observable state of client identity, application/service, and the requesting asset—and may include other behavioral and environmental attributes.
- The enterprise monitors and measures the integrity and security posture of all owned and associated assets.
- All resource authentication and authorization are dynamic and strictly enforced before access is allowed.
- The enterprise collects as much information as possible about the current state of assets, network infrastructure and communications and uses it to improve its security posture.
In this blog, we’ll look at the Zero Trust authentication and authorization pieces of this architecture. As stated before, a subject (end-user, application) can only access a resource once its identity is verified (authentication) and it’s determined that the authenticated subject is allowed to access the resource (authorization). As more organizations adopt microservice architectures, it would be interesting to think about Zero Trust in that service-to-service context. For example, how do you determine whether your frontend service is allowed to communicate with your database service? To achieve this you would first have to assign a unique identity to each service and then use that identity to determine if it can perform the requested action. This is where you can leverage Envoy, SPIFFE/SPIRE and Open Policy Agent (OPA) as the foundations to implement a Zero Trust Architecture.
Zero Trust with Envoy, SPIRE and OPA
Before we look at how to use OPA, Envoy and SPIFFE/SPIRE to implement Zero Trust, let us first briefly introduce these projects.
Envoy is a L7 proxy and communication bus designed for large modern service oriented architectures. Envoy supports an External Authorization filter which calls an authorization service to check if the incoming request is authorized or not. This feature makes it possible to delegate authorization decisions to an external service and also makes the request context available to the service.
SPIFFE, the Secure Production Identity Framework for Everyone, is a set of open-source standards for securely identifying software systems in dynamic and heterogeneous environments. Systems that adopt SPIFFE can easily and reliably mutually authenticate wherever they are running. SPIRE (the SPIFFE Runtime Environment) is a toolchain for establishing trust between workloads across a wide variety of platforms.
Open Policy Agent (OPA) is an open source, general-purpose policy engine created by Styra that enables unified, context-aware policy enforcement across the entire stack. OPA’s high-level declarative language Rego allows authoring of fine-grained security policies and is purpose built for reasoning about information represented in structured documents.
Let’s revisit our original example involving a frontend service and database service and now we’ll try to enforce a policy that says, “only the frontend service is allowed to communicate with the database service”. As you may remember one of the tenets of Zero Trust is to authenticate and authorize every request before allowing resource access. First let’s briefly understand the below setup and walkthrough the end-to-end request flow:
Setup:
1) Administrator deploys the services that make up the application. In this case frontend and database
2) The deployment injects OPA, Envoy and SPIRE in each service’s pod
3) SPIRE assigns unique identities to the services in the form of a SPIFFE ID
4) OPA supports Envoy’s External Authorization API
End-to-End flow
1) An end-user tries to access the frontend service
2) This request is handled by the frontend service’s Envoy instance. Envoy will call OPA for an authorization decision and if OPA allows the request it is forwarded to the frontend service container
3) Let’s assume that the frontend service’s business logic dictates that it communicate with the database service to fetch some data
4) So now the frontend service’s Envoy will send a request to the database service. This request is intercepted by the database service’s Envoy.
5) database service’s Envoy will send this request to OPA. This request will include the identity of the caller (ie. frontend service)
6) OPA will now evaluate the request based on the loaded policy and data. If allowed, the request is forwarded to the database service
7) database service sends data back to the frontend service which then presents it to the end-user.
For the sake of brevity, we have left out some details like end-user authentication, workload registration etc. from the above description. In this blog, we’ll focus on steps 3-6 of the end-to-end flow and explain the Zero Trust principles involved.
How this works: Authentication
Secure communication between the frontend and database service is established by configuring the Envoy proxies in each container to establish a mTLS connection with each other. Envoy retrieves client and server TLS certificates and trusted CA roots for mTLS communication from a SPIRE Agent which implements an Envoy SDS. The agent in-turn fetches this information from the SPIRE Server and makes it available to an identified workload. In the above example, SPIRE provides each workload an identity, in the form of a SPIFFE ID embedded in the TLS certificate, to facilitate mTLS communication. The SPIFFE ID of each workload can then be used by OPA to build the authorization policy. For example, the SPIFFE ID for the frontend and database service can be something like spiffe://acme.com/frontend and spiffe://acme.com/database respectively.
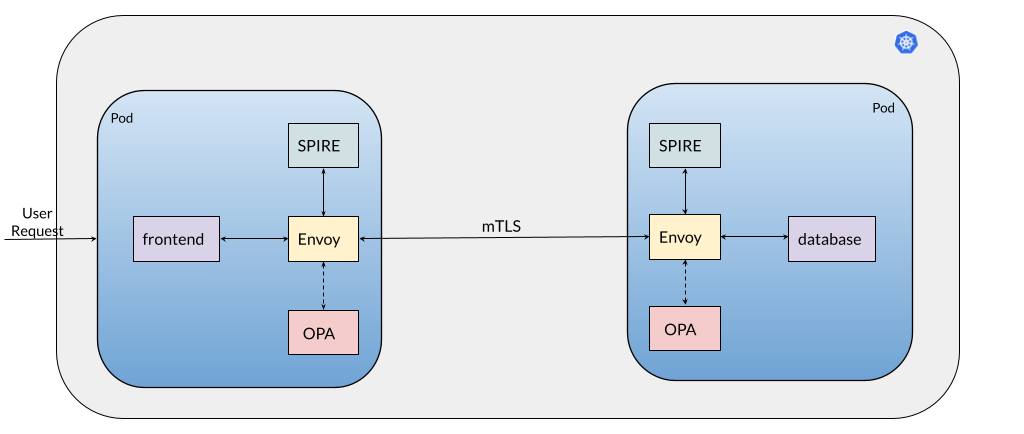
How this works: Authorization
Now that SPIRE has assigned trusted identities to each of the services, we can now move on to the next step of our Zero Trust framework – Authorization. Envoy’s external Authorization filter will pass on every request to OPA so that OPA can determine whether to allow the request or not. The request context contains information such as the source of a network activity, destination of a network activity, the network request (eg. http request). All this information can be used by OPA to make an informed decision about the fate of the incoming request received by Envoy. The policy we want to enforce states that “only the frontend service is allowed to communicate with the database service”. This policy can be enforced by the database service and is defined as below:
Notice that the policy fetches the SPIFFE ID the X-Forwarded-Client-Cert (XFCC) proxy header. This is possible because the header is injected by the Envoy proxy of the frontend service and validated by the Envoy proxy of the database service.
To recap, within a matter of milliseconds, we verified our workloads using the authentication framework provided by SPIFFE/SPIRE and then leveraged Envoy’s External authorization filter which allowed OPA to make an authorization decision (eg. allowed/denied) about the incoming request.
And that’s it!
Zero Trust is a concept that is created to enhance the security profile of your applications, environment and infrastructure, to help prevent lateral movement from a threat actor and foster least-privilege access methodology. The Zero Trust mantra is trust no one. It’s a collection of technologies rather than a single architecture. In this blog we looked at one of the key principles of Zero Trust around authenticating and authorizing every request before a service is allowed to access the resource. We defined a simple OPA policy that demonstrated how service to service communication can be protected. You can easily get started on the Zero Trust path with the sample workflow described in this blog, and we’ll be there to guide you through this journey.
Looking to get started?
Styra Academy – More than 30 free, self-paced online courses to help you learn how to enforce authorization policy across your cloud-native stack, built by the creators of OPA.
OpenPolicyAgent. – The OPA website, where you may find OPA documentation, downloads, and the OPA Blog.
The Rego Playground – Rego (pronounced “ray-go”) is OPA’s policy language. Using the Playground, you may view policy examples, execute policies with input and data, and publish your policies to share and collaborate.
Styra DAS – Request a custom demo from our team. Styra DAS is a great way to get started using OPA. It provides sample apps, sample policies, in addition to quickstarts that allow you to spin up new OPA’s for common use cases.
FAQs
What is the best way to implement a Zero Trust policy?
While Zero Trust can involve a constellation of technologies, users often find that Open Policy Agent (OPA) is a well-vetted way to enforce Zero Trust authorization policies at different access points in an application — whether at the API gateway, for example, or at individual microservice APIs. Using OPA, the Zero Trust concept, “never trust, always verify” is possible to implement in a practical way.
Why do I need Zero Trust?
Enterprises, particularly in highly regulated sectors, are embracing Zero Trust approaches to fulfill strict security and compliance requirements within modern applications. While approaches to Zero Trust differ, enterprises are aligned that a “never trust, always verify” approach to application security is essential, and open-sources tools like OPA offer a practical way forward for their needs.
What is a Zero Trust Security Architecture?
The Zero Trust Architecture was established as a standard by NIST SP 800-207. It lays our practical architectural requirements for a system to meet Zero Trust principles, namely that every object is both authenticated and authorized before accessing any resource in the system. OPA offers one mechanism, together with identity providers, for enforcing Zero Trust policies in such an architecture.