THEY DID WHAT!? Auditing a security breach using Enterprise OPA decision logs and AWS Athena
What you will learn
You will learn how to use the Enterprise OPA Enhanced Decision Logs feature to configure Enterprise OPA (EOPA) to upload decision logs to an AWS S3 bucket so that they can be queried using AWS Athena. In mid to large sized deployments of EOPA, immense quantities of decision logs can be generated, necessitating big data tools such as Athena. This can be useful for security breach auditing, auditing access decisions, and for business intelligence in general.
We will explore an imagined incident response scenario, where an organization has already configured EOPA to upload decision logs to S3 and needs to conduct an enterprise security breach analysis by auditing access decisions retroactively. We will use Athena to write and execute SQL-like queries (powered by Trino and Presto) against these decision logs to audit what happened during the incident.
Use Cases
This blog can help organizations producing large volumes of decision logs using OPA, who want to query their decision logs occasionally to answer specific business or regulatory questions, like “when did user X access resource Y during Q1 of last year”. This guide does not address “streaming” or “real time” needs such as “call this web hook each time user X accesses resource Y”.
This guide is intended to be as general as possible, so the input and result documents are treated as “black boxes”. Examples in this guide suppose an input document with a few string fields: subject, resource, action, country code, region, and client IP. That the output object is simply a boolean “allowed” field, and a message describing the reason for the decision. This is for illustrative purposes only; the input and output documents are freeform when using [E]OPA in the real world. Although assuming a specific structure for the input and result documents could open up some additional avenues for performance and cost optimizations, it would also make this guide much less generally applicable.
Act I
Text written in italics, like this is part of our fictional story, to make things fun and provide some color & motivation. If that’s not your thing, you can safely skip the italics parts without missing anything technical.
The shrill wail of your smartphone plucks you from your slumber like a claw machine grabbing a prize, the blue glow of its screen the only light aside from the street lamp shining tentatively through your blinds. You fumble for your phone in the darkness, squinting blearily against the glare. Your blood runs cold – a PagerDuty Alert. You summon Slack to investigate the incident: Dr. Evil has breached your organization’s security and now your compliance officer is on the warpath. Half of the engineering team is already awake; it’s critical that you determine what was compromised before the doors open at 9AM sharp – 6 hours. Fortunately, you use Enterprise OPA for all of your authorization, and the decision logs are ripe for the querying, having been dutifully uploaded to S3 over the past weeks, months, and years since you adopted EOPA by the Enhanced Decision Logs feature. You roll up the sleeves on your nightshirt. It’s time to get to work…
Prerequisites
As you SSO into the various accounts to respond to the incident, you reflect on your work all those months ago, setting up EOPA and S3, permitting yourself a brief grin of reassurance in knowing that you will be able to answer your compliance officer’s questions in time.
Create an AWS S3 Bucket
You will need to create an AWS S3 bucket where EOPA should send decision logs. Before you proceed, make sure you know the name of your bucket, the S3 endpoint your bucket is accessed at, and your AWS access key.
EOPA Configuration
You can learn more about configuring the AWS S3 decision log sink in the docs. Below is an example of a simple EOPA configuration suitable for uploading decision logs into S3 that are queryable by AWS Athena. Notice that batching is enabled, and that the batching format is set to “lines” – this is important because it causes multiple decision logs (up to 10s worth, or 2048, whichever is lesser) to be combined in each S3 object. This improves performance when using tools such as Athena. You should experiment with the at_period and at_count settings to dial in a batch size that works best with your use case and workload.
decision_logs:
plugin: eopa_dl
plugins:
eopa_dl:
buffer:
type: memory
output:
type: s3
bucket: # CHANGEME # e.g. eopa-athena-tutorial-01
endpoint: # CHANGEME # e.g. https://s3.amazonaws.com
force_path: true
region: # CHANGEME # e.g. us-east-1
access_key_id: "CHANGEME"
access_secret: "CHANGEME"
batching:
at_period: "10s"
at_count: 2048
format: linesEOPA Decisions
It is important to understand just what it is that EOPA is logging into S3, as this information is needed to set up Athena properly. Consider a single EOPA decision:
{
"bundles": {
"./bdir/": {}
},
"decision_id": "320e2820-1628-4819-b82c-eca7e48b21b9",
"input": {
"action": "PUT",
"client_ip": "57.239.148.160",
"country": "FRA",
"region": "us-east-2",
"resource": "/sales/prospects/black_mesa",
"subject": "sarahsmith"
},
"labels": {
"id": "3f218a4c-5776-40d5-82e4-f4e9524c0610",
"type": "enterprise-opa",
"version": "0.54.0"
},
"metrics": {
"counter_regovm_eval_instructions": 230,
"counter_server_query_cache_hit": 1,
"timer_rego_input_parse_ns": 13125,
"timer_regovm_eval_ns": 51500,
"timer_server_handler_ns": 112959
},
"nd_builtin_cache": {},
"path": "authz/decision",
"result": {
"allowed": true,
"message": "sales may mutate sales records",
"roles": [
"sales"
]
},
"timestamp": "2023-07-11T17:01:42.252749Z"
}
The input and result fields are freeform, and depend on the Rego code used, the query, and the data provided in the input document. For purposes of this tutorial, many decisions similar to the one above were shown above.
The input document contains a subject, resource, and action which are chosen randomly from a list. The client_ip field contains a randomized ipv4 address. The region field contains a random AWS region, and finally the country field contains a random ISO3166 country code.
The output obtained by the path authz/decisions is always an object with a boolean allowed field, a message explaining the allow or deny, and a list of roles associated with the user.
These randomized example decisions are meant to be suggestive of an API authorization use case for EOPA, with some imagined HTTP middleware calling out to an EOPA sidecar to decide if API requests should be allowed or not.
We previously configured EOPA to store decisions such as the one above in line-delimited JSON files in S3. Each S3 object will contain a batch of one or more decision objects, formatted as a single line per JSON object. For example, the following is an excerpt from one such S3 object:
{"bundles":{"./bdir/":{}},"decision_id":"55baedd4-3de5-46c3-9743-4025f3200a39","input":{"action":"DELETE","client_ip":"159.70.211.120","country":"USA","region":"ap-northeast-3","resource":"/sarahsells/documents/slides/gophercon27","subject":"sarahsmith"},"labels":{"id":"3f218a4c-5776-40d5-82e4-f4e9524c0610","type":"enterprise-opa","version":"0.54.0"},"metrics":{"counter_regovm_eval_instructions":216,"counter_server_query_cache_hit":1,"timer_rego_input_parse_ns":12583,"timer_regovm_eval_ns":41000,"timer_server_handler_ns":80459},"nd_builtin_cache":{},"path":"authz/decision","result":{"allowed":false,"message":"requests are denied by default","roles":["sales"]},"timestamp":"2023-07-11T17:01:42.255262Z"}
{"bundles":{"./bdir/":{}},"decision_id":"001ff804-5b9e-48c4-9a5f-f9d3c9173051","input":{"action":"PUT","client_ip":"36.61.22.180","country":"ISL","region":"ap-northeast-1","resource":"/emilybrown3456/private/apitokens","subject":"sarahlopez5678"},"labels":{"id":"3f218a4c-5776-40d5-82e4-f4e9524c0610","type":"enterprise-opa","version":"0.54.0"},"metrics":{"counter_regovm_eval_instructions":228,"counter_server_query_cache_hit":1,"timer_rego_input_parse_ns":14417,"timer_regovm_eval_ns":61625,"timer_server_handler_ns":99584},"nd_builtin_cache":{},"path":"authz/decision","result":{"allowed":false,"message":"requests are denied by default","roles":[]},"timestamp":"2023-07-11T17:01:42.258229Z"}
{"bundles":{"./bdir/":{}},"decision_id":"6d03a164-7900-407c-9da3-4fc74150681d","input":{"action":"PUT","client_ip":"245.249.234.43","country":"HUN","region":"ap-south-2","resource":"/bobjohnson1234/data/experiments/45763.dat","subject":"emilybrown3456"},"labels":{"id":"3f218a4c-5776-40d5-82e4-f4e9524c0610","type":"enterprise-opa","version":"0.54.0"},"metrics":{"counter_regovm_eval_instructions":228,"counter_server_query_cache_hit":1,"timer_rego_input_parse_ns":15625,"timer_regovm_eval_ns":80250,"timer_server_handler_ns":129875},"nd_builtin_cache":{},"path":"authz/decision","result":{"allowed":false,"message":"requests are denied by default","roles":[]},"timestamp":"2023-07-11T17:01:42.258923Z"}
TIP: While Athena prefers JSON lines, some tools that can accept JSON do not. Fortunately, you can easily convert JSON lines to an array of JSON objects with this shell one-liner if you need to: awk 'BEGIN {printf("[")} NR>1 {printf(",\n")} {printf("\t%s", $0)} END{printf("\n]\n")}' < input.jsonl > output.json
Each decision batch is stored in S3 with certain metadata included in the path as Apache Hive style key-value pairs. For example, the URI for a single batch of decisions might look like:
s3://eopa-athena-tutorial-01/eopa=3f218a4c-5776-40d5-82e4-f4e9524c0610/first_ts=1689094902/last_ts=1689094905/batch_id=c8c4466f-20a0-4a8b-8471-5b2d88fb0ce1.jsonl
The first_ts and last_ts fields contain the UNIX timestamp (with seconds precision) of the first and last decision in the batch. This is useful, because we can use these fields to accelerate Athena queries based on decision timestamps
You can learn more about how decisions work in [E]OPA here.
Act II
You cast about your development environment for some tool that can help you. You know the data you need is already in S3 – and there’s a lot of it. Way too much to download to your laptop in time. Through the mental haze of your disrupted slumber, a dim memory unfurls: your Big Data class back in school… but what was that tool – it would be perfect – a SQL engine that could operate directly on the data you already have in S3. Like a flash of lightning, revelation dawns on you: AWS Athena will let you write SQL against your EOPA decision stored in S3.
Configure Athena
Open Athena from the AWS management console. Select “Create”, then “S3 bucket data”.
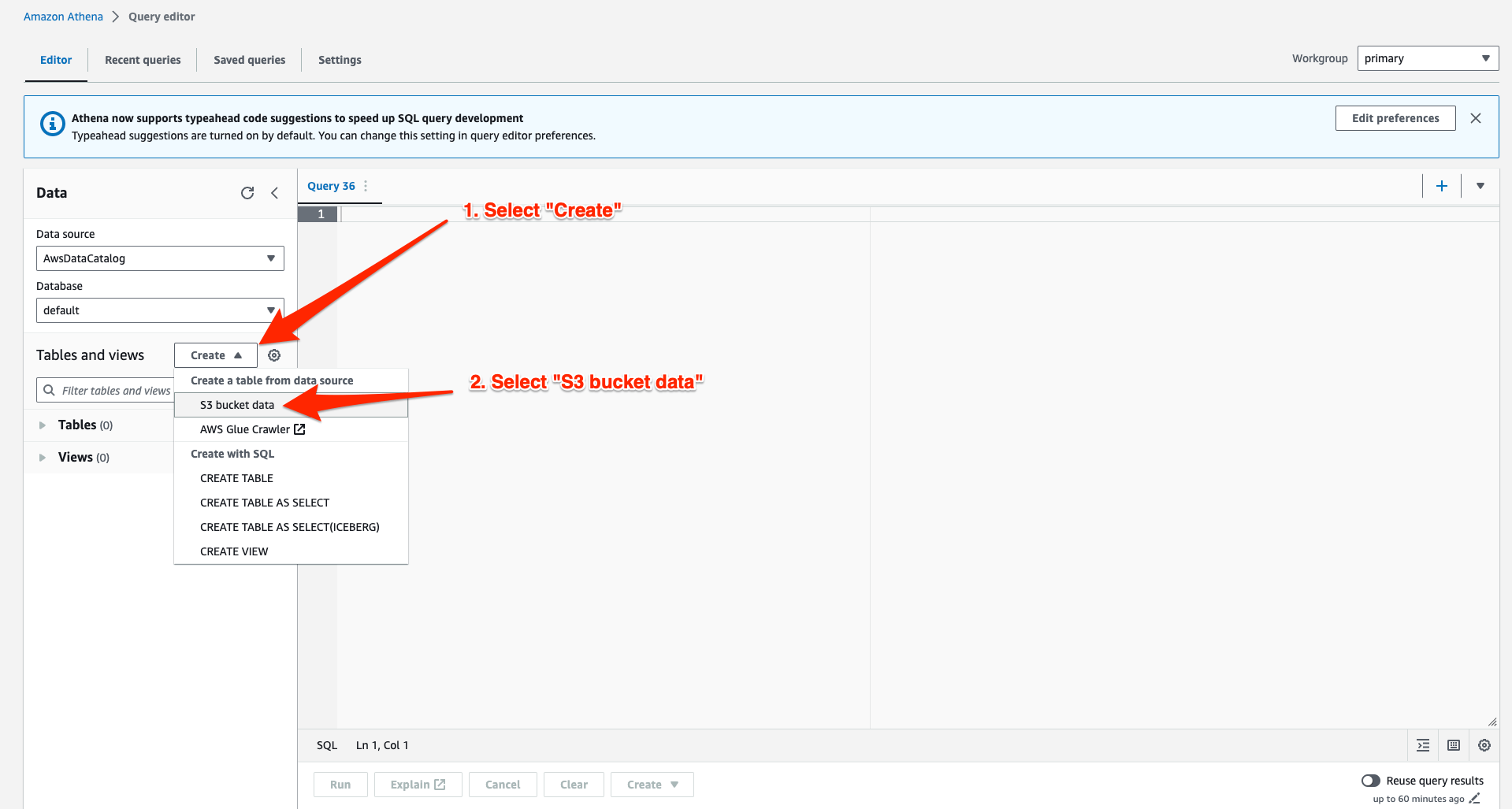
Fill in a “Table name”, optionally provide a description, and either choose an existing database or create a new one. The screenshot below shows a table named eopa_athena_tutorial_table_01, which will be created in a new database called eopa_athena_tutorial_db.
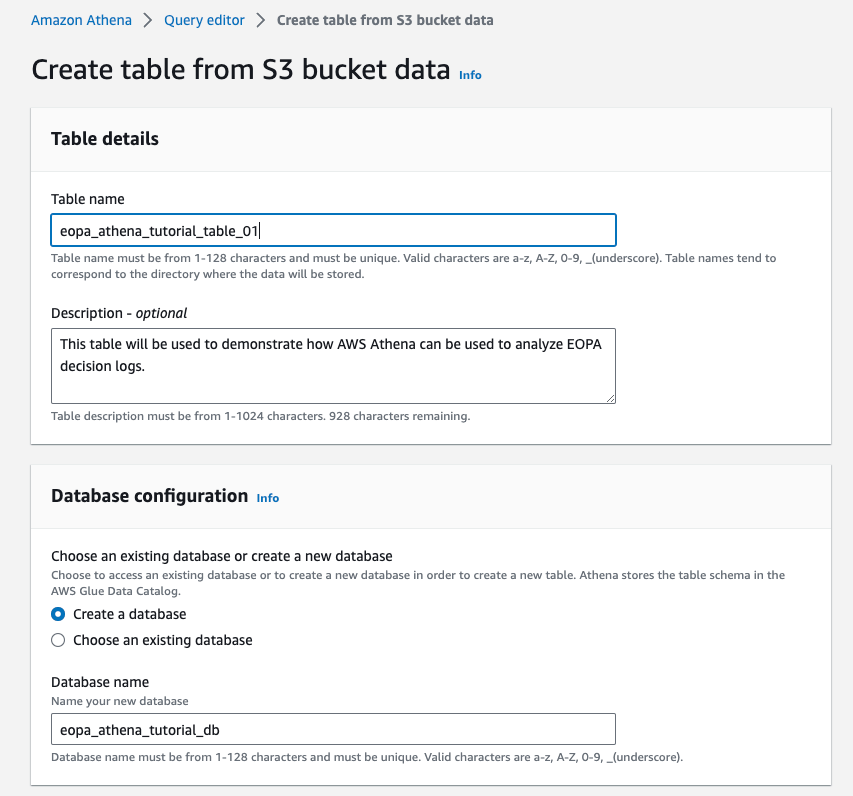
Select the S3 bucket you configured EOPA to write logs into. For example, the screenshot below uses s3://eopa-athena-tutorial-01. Your S3 URI is likely to be different. If you’re not sure what the correct S3 URI is, return to the Create an S3 Bucket section of this guide.
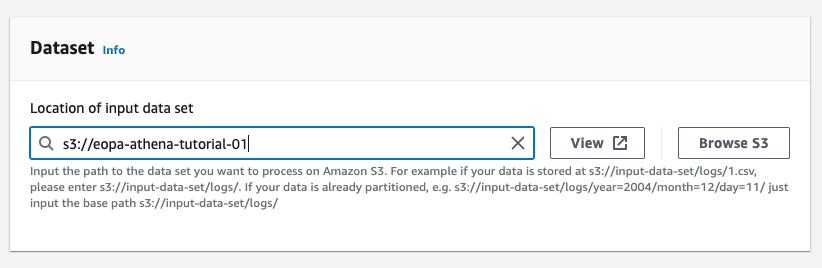
Configure the Data format as follows:
- Table type: Apache Hive
- File format: JSON
- SerDe library: org.openx.data.jsonserde.JsonSerDe
- SerDe properties:
- ignore.malformed.json: TRUE
- NOTE: this will cause S3 objects with invalid JSON to be omitted from your query results, rather than causing an error. If you would prefer any malformed JSON to be ignored instead, set this field to FALSE.
- dots.in.keys: FALSE
- case.insensitive: TRUE
- mapping: TRUE
The screenshot below shows these properties being configured as described above:
In the “Column details” section, create the following columns:
| Column name | Column type |
| decision_id | string |
| input | string |
| path | string |
| result | string |
| timestamp | string |
| labels | map<string,string> |
| metrics | map<string,bigint> |
The screenshot below shows the columns properly configured, according to the table above.
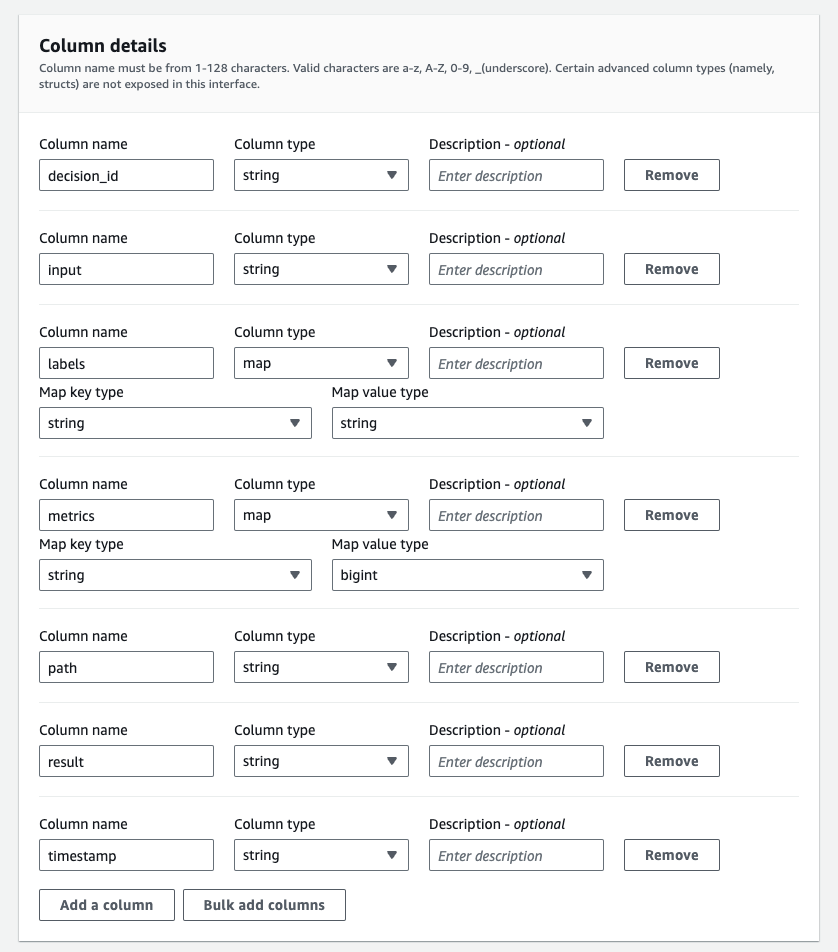
Expand the “Partition details” section, then create the following partition columns:
| Column name | Column type |
| eopa | string |
| first_ts | bigint |
| last_ts | bigint |
TIP: make sure you get this part right. If the keys in the S3 object URLs do not match up exactly with the column names in your Athena partitions, then you won’t be able to SELECT any data.
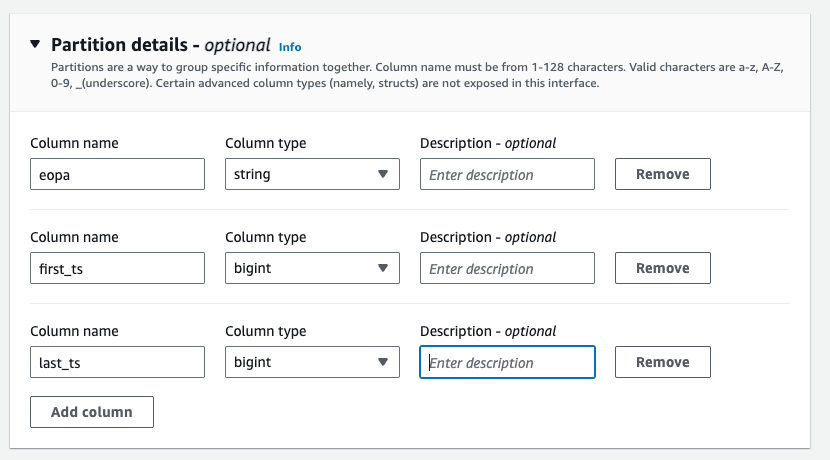
Click the “Create table button”.
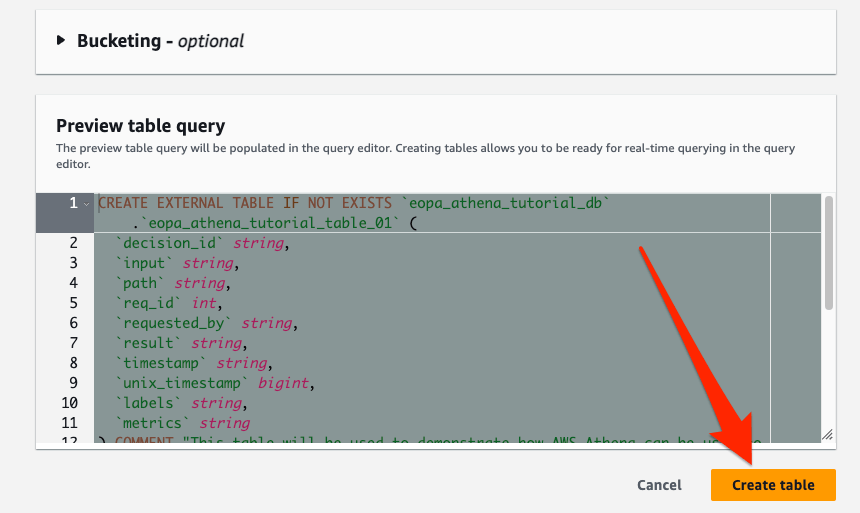
You should be dropped back in the Athena editor, where you will see the SQL the setup wizard generated for you. It should look something like:
CREATE EXTERNAL TABLE IF NOT EXISTS `eopa_athena_tutorial_db`.`eopa_athena_tutorial_table_01` (
`decision_id` string,
`input` string,
`labels` map < string,
string >,
`metrics` map < string,
bigint >,
`path` string,
`result` string,
`timestamp` string
)
PARTITIONED BY (
`eopa` string,
`first_ts` bigint,
`last_ts` bigint
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'ignore.malformed.json' = 'FALSE',
'dots.in.keys' = 'FALSE',
'case.insensitive' = 'TRUE',
'mapping' = 'TRUE'
)
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://eopa-athena-tutorial-01/'
TBLPROPERTIES ('classification' = 'json');
Note that it is also possible to skip the interactive wizard, and simply execute this SQL directly to create the table. If you do this, remember to update the database and table name, as well as the LOCATION to appropriate values for your setup.
Select the database you created in the left hand sidebar, and also create a new query. Enter MSCK REPAIR TABLE eopa_athena_tutorial_db.eopa_athena_tutorial_table_01 (remember to change the database and table name as needed) and select “Run”. This will rebuild Athena’s index of your partitions.
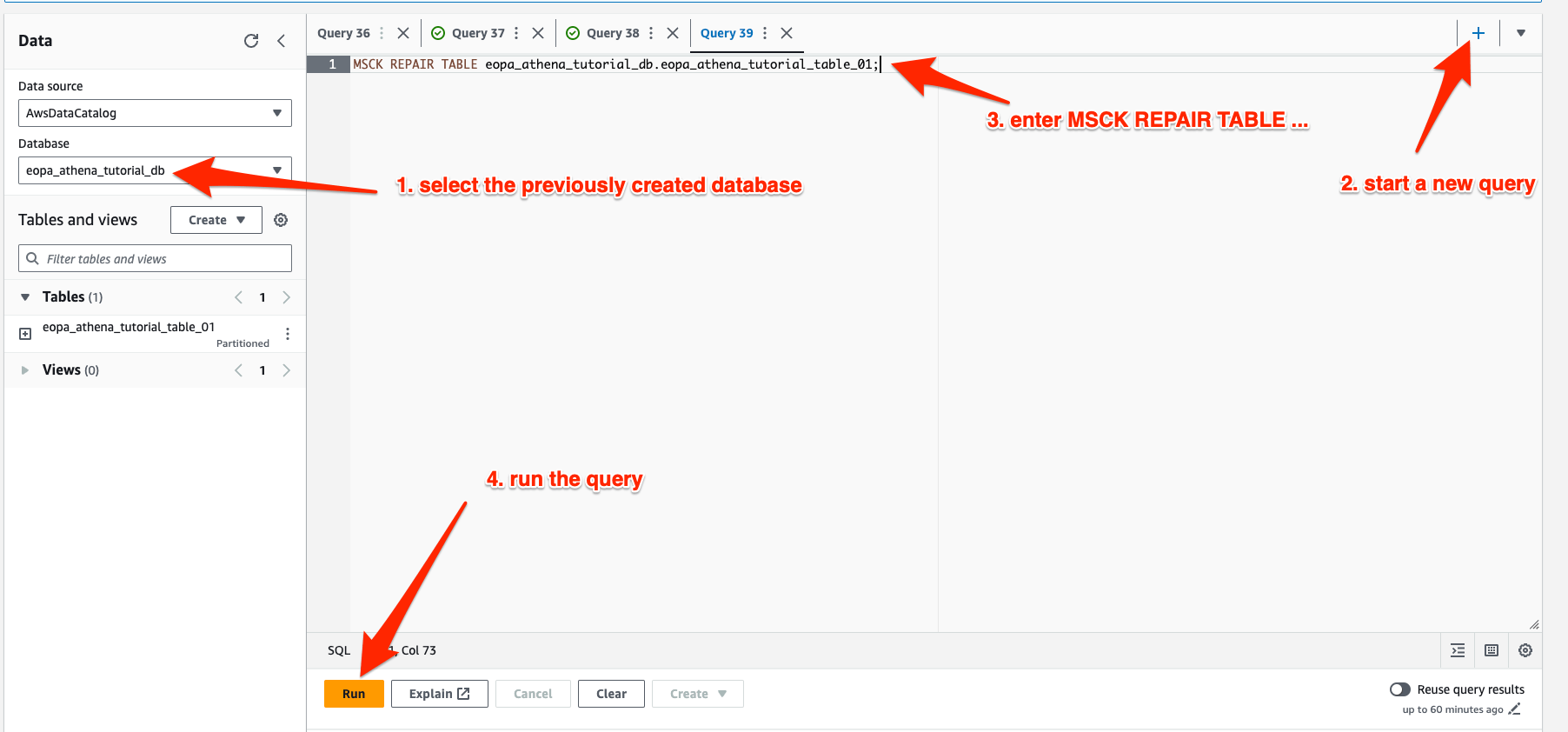
Once the MSCK REPAIR TABLE query completes, you are ready to begin querying your EOPA decisions stored in S3.
To ensure everything worked correctly, select the 3 vertical dots next to the table in the sidebar, then select “preview table” and run the resulting query.
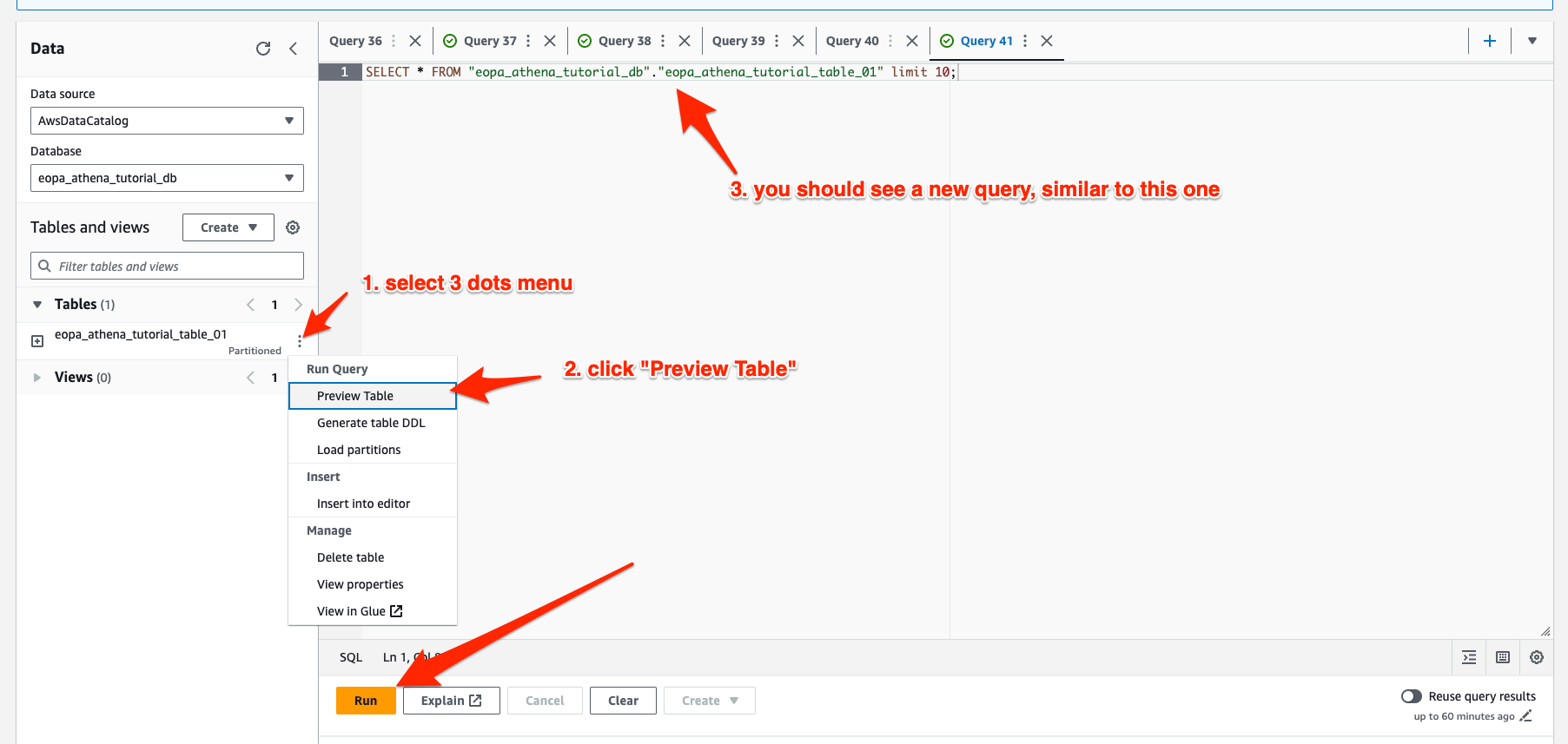
Subsequently, you should see the first 10 decisions show up in the output area, similar to the image below:
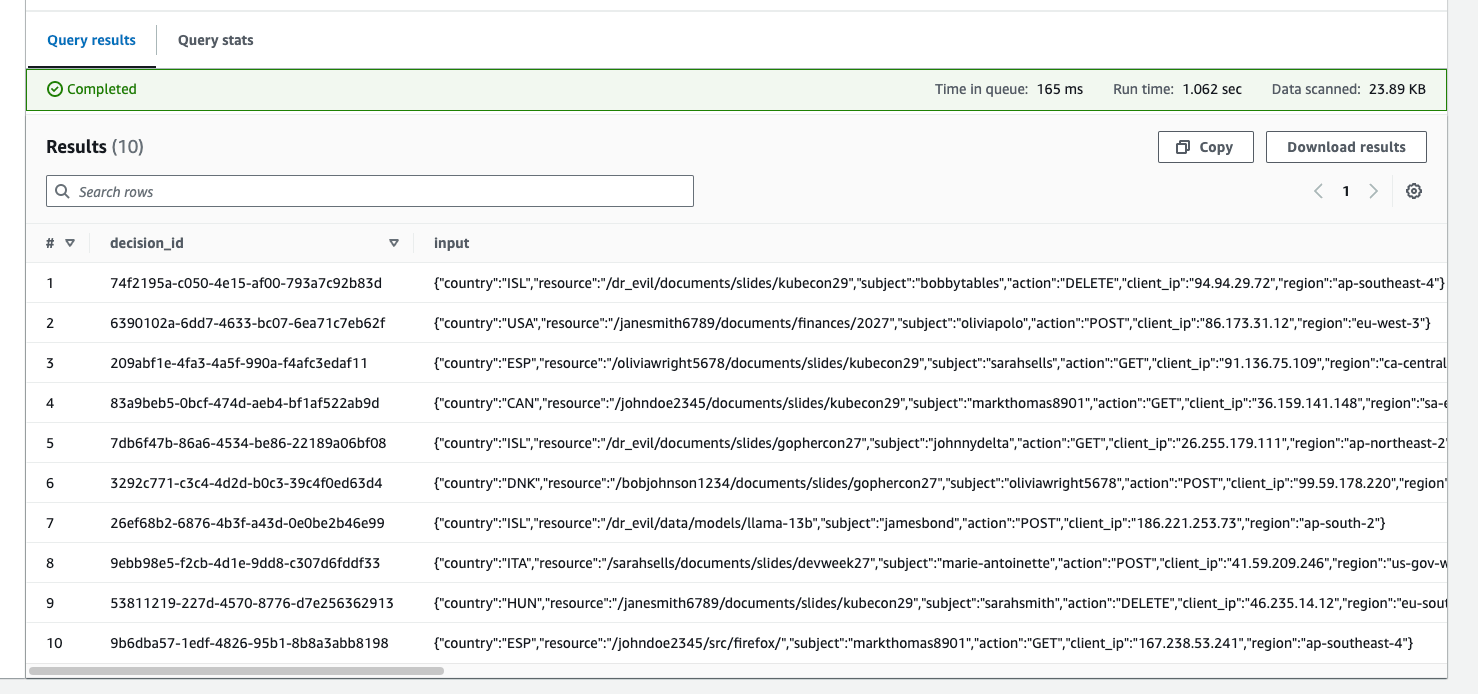
If you don’t see any results when you use the preview, it means you have likely made a configuration error. Pay careful attention to the column names and types, as mistakes in those areas can result in Athena returning 0 results to your query without surfacing an explicit error.
Act III
Your fingers shake slightly from the exhaustion and stress as you press the “Run” button. The dim air of your bedroom feels as thick and heavy as syrup. Time seems to slow down, the seconds spent executing the query stretching out as if they were months. In an instant, it’s over and the results pane is filled with records. Just ten for now, a forebear of what is to come. The cursor in the query window blinks enticingly, as if it knows the power it will soon unleash at your behest.
You flip back to Slack to reread your compliance officer’s message again. The incident response team reacted quickly to lock Dr. Evil out of your network. Your critical systems were only compromised for a few minutes. Like bookends placidly holding up a series of horror novels, ignorant of the darkness sandwiched between them, two timestamps shine off-white-on-dark-gray in the midst of the DM: 2023-07-11T16:55:00Z and 2023-07-11T17:00:00Z. Though only a short span of time, this still constitutes hundreds of thousands of decisions in your production environment.
Querying Decisions With Athena
Selecting all decisions within a time range
To take advantage of the performance and cost benefits of our partitioning, it is necessary to exercise care; though there is a timestamp field for each decision, that isn’t one of our partition columns. Instead, we need to utilize the first_ts and last_ts columns which are partition columns. The represent the UNIX timestamp in seconds of the first and last timestamp of the decisions within a batch.
In this example, we select all decisions between 2023-07-11T16:55:00Z and 2023-07-11T17:00:00Z, a time range which happens to have many decisions in it in the test data used for this guide. Notice that the start and end timestamps have to be duplicated twice, this is because the Athena SQL engine does not support variables or constants.
SELECT
*
FROM
"eopa_athena_tutorial_db"."eopa_athena_tutorial_table_01"
WHERE
first_ts >= to_unixtime(from_iso8601_timestamp('2023-07-11T16:55:00Z'))
AND
-- One might think last_ts would make more sense here, but remember that
-- it's possible that a decision we're interested in could be in a batch
-- which has a first_ts before the end of our time range, and a
-- last_ts after the end of our time range.
first_ts <= to_unixtime(from_iso8601_timestamp('2023-07-11T17:00:00Z'))
AND
-- These last two conditions narrow down the timestamps within the
-- selected partition(s). We could omit these if we were OK with having
-- an error of up to +- the duration of a single batch - that might be
-- faster in a situation where the typical batch duration is much
-- smaller than the time range of interest.
from_iso8601_timestamp(timestamp) >= from_iso8601_timestamp('2023-07-11T16:55:00Z')
AND
from_iso8601_timestamp(timestamp) <= from_iso8601_timestamp('2023-07-11T17:00:00Z')
Selecting decisions in a time range with a specific subject
Of course just getting all the decisions in a time range is not enough. To figure out what Dr. Evil did, you’ll need to filter the decision logs during the breach based on the user account making the API requests.
In this example, we will search for all decisions within a time range as above, but we’ll also examine the JSON data in the input document to decide if a particular subject we are interested in was making the request. This query searches for decisions in the same time range as before, where the “subject” field of the input document is “dr_evil”.
SELECT
*
FROM
"eopa_athena_tutorial_db"."eopa_athena_tutorial_table_01"
WHERE
first_ts >= to_unixtime(from_iso8601_timestamp('2023-07-11T16:55:00Z'))
AND
first_ts <= to_unixtime(from_iso8601_timestamp('2023-07-11T17:00:00Z'))
AND
from_iso8601_timestamp(timestamp) >= from_iso8601_timestamp('2023-07-11T16:55:00Z')
AND
from_iso8601_timestamp(timestamp) <= from_iso8601_timestamp('2023-07-11T17:00:00Z')
AND
-- Extract the "subject" field from the input column, a JSON string
-- representing the input document used in the request to OPA. We
-- must use the CAST keyword because json_extract returns a special
-- 'json' type which cannot be directly compared to a string (varchar)
-- literal.
CAST(json_extract(input, '$.subject') AS varchar) = 'dr_evil'
Selecting decisions within a time range, with a specific subject and CIDR
A push notification slides into view from beyond the boundless pool of nothingness that surrounds your laptop’s LCD panel. Another slack notification. DevOps has been chasing Dr. Evil’s connection logs through the company firewall, and they’ve determined that the attack originated from somewhere in the 10.0.0.0/8 subnet. The net grows ever tighter as you integrate this new detail into your query.
In this example, we perform the same search as before, but we will also limit the CIDR subnet of the “client_ip” field of the input to 10.0.0.0/8.
SELECT
*
FROM
"eopa_athena_tutorial_db"."eopa_athena_tutorial_table_01"
WHERE
first_ts >= to_unixtime(from_iso8601_timestamp('2023-07-11T16:55:00Z'))
AND
first_ts <= to_unixtime(from_iso8601_timestamp('2023-07-11T17:00:00Z'))
AND
from_iso8601_timestamp(timestamp) >= from_iso8601_timestamp('2023-07-11T16:55:00Z')
AND
from_iso8601_timestamp(timestamp) <= from_iso8601_timestamp('2023-07-11T17:00:00Z')
AND
CAST(json_extract(input, '$.subject') AS varchar) = 'dr_evil'
AND
-- json cannot be directly cast to an IPADDRESS, but we can cast it to
-- a varchar first and then cast that to an IP.
contains('10.0.0.0/8', CAST(CAST(json_extract(input, '$.client_ip') AS varchar) AS IPADDRESS))
Cross-Referencing Other Data with Joins
Somewhere in the pre-dawn hours, a gentle twilight barely creeping over the horizon of some distant timezone, an IAM team lead is stirring, like you, roused from her slumber by the obstinate cry of a PagerDuty alert. This fact is unknown to you, until you receive her analysis of the situation. “You can’t just assume Dr. Evil was using his own account”, she warns. “He’s a tricky fellow, he might have compromised the accounts of some legitimate users along the way!”. An S3 URL quickly follows: JSON data, carefully prepared while you were busy setting up Athena. For each employee, it lists the countries they are authorized to work from. “See now, Dr. Evil might be using seven VPNs, but our middleware injects the country of origin into each request. He might have the credentials right, but the incorrect country codes will give him away.”.
In some situations, it might be necessary to cross-reference decision logs from EOPA with other data, perhaps exported or uploaded from some other piece of infrastructure. To demonstrate how to go about this using Athena, I created a table associating certain users (subjects) with one or more countries, perhaps representing countries they are authorized to make requests from. While analyzing decision logs, one might wish to select anomalous decisions such as once where the decision was allowed but the requests country wasn’t on the list for the request subject, as this might indicate a malicious actor is using stolen credentials.
SELECT
decs.decision_id,
decs.input,
decs.labels,
decs.metrics,
decs.path,
decs.result,
decs.timestamp,
decs.eopa,
decs.first_ts,
decs.last_ts
FROM
"eopa_athena_tutorial_db"."eopa_athena_tutorial_table_01" AS decs
INNER JOIN (
-- The eopa_athena_tutorial_user_countries table has 2 columns,
-- "subject" and "country". If a subject is associated with multiple
-- countries, more than one row with the same subject is used.
--
-- Here we aggregate the countries for each subject into an array valued
-- column, so that there is only 1 row per subject. This could have
-- been avoided by structuring the data differently in the S3 bucket,
-- however this approach demonstrates how nested SELECT statements
-- can be used to manipulate data during joins.
SELECT
subject,
array_agg(country) AS countries
FROM
"eopa_athena_tutorial_db"."eopa_athena_tutorial_user_countries"
GROUP BY
subject
) AS countries
ON
CAST(json_extract(decs.input, '$.subject') AS varchar) = countries.subject
WHERE
first_ts >= to_unixtime(from_iso8601_timestamp('2023-07-11T16:55:00Z'))
AND
first_ts <= to_unixtime(from_iso8601_timestamp('2023-07-11T17:00:00Z'))
AND
from_iso8601_timestamp(timestamp) >= from_iso8601_timestamp('2023-07-11T16:55:00Z')
AND
from_iso8601_timestamp(timestamp) <= from_iso8601_timestamp('2023-07-11T17:00:00Z')
AND
-- countries.countries is the array of countries associated with the
-- request subject (input.subject) which we constructed during the join.
NOT contains(countries.countries, CAST(json_extract(decs.input, '$.country') AS varchar))
AND
CAST(json_extract(decs.result, '$.allowed') AS boolean) = trueTheory Of Operation
AWS Athena is a “big data” tool, which allows the user to write SQL-like queries over data stored in various ways in an AWS account, especially S3 objects containing structured data in various common formats. Because Athena queries the live data – that is it does not translate the data and store the translated copy elsewhere – the results of an Athena query are always live and up-to-date, and no additional costs are incurred for storing duplicated data. However, Athena is billed by the amount of data it has to scan, so structuring data and queries in a way to minimize this is important to keep costs down.
Because Athena is “just” a query engine, and does not include a traditional RDBMS backend, it is not possible to create indices, instead it is necessary to leverage a feature Athena calls partitioning wherein additional metadata is associated with the S3 objects it is to query, and can be used to eliminate certain objects from consideration to improve performance and reduce costs by scanning less data. For example, you might attach a tag such as zone=us-west-3, partition on the zone column, and subsequently any Athena queries with a clause like WHERE zone = 'us-west-3' can scan only those S3 objects with a matching key value pair associated. EOPA automatically inserts appropriate key-value pairs to partition the data by the EOPA’s UUID, and the timestamps of the first and last decisions in each batch. EOPA uses UNIX timestamps rather than time strings, so that searching and sorting can be done by integer math operations without any string parsing, and also to avoid needing to encode timestamp strings into path elements for partition key value pairs.
Enterprise OPA supports logging decisions to S3 via its enhanced decision logs feature. Athena performs best with smaller numbers of larger S3 objects. Therefore, it is suggested to use a larger batch size, ideally targeting tens of MBs of decisions per batch. There is a tradeoff in determining batch size though, namely that if EOPA crashes or the underlying server, VM, or container fails before a batch is uploaded, all of the decisions in that batch could be lost. Fortunately, EOPA can mitigate against this failure mode via the disk buffer type.
Act IV
Dr. Evil broods in his lair, printed reports strewn across those glossy, striated surface of massive hardwood conference table. His fist is clenched so tight his knuckles are as white as the papers. Foiled again! His evil plans seemed to be coming to fruition perfectly, but his target quickly detected and responded to his multi-pronged malware intrusion and simultaneous phishing attacks. Even the modest damage he managed to deal was already being rolled back due to fine-grained access logging. Those darn kids these days with their defense-in-depth… zero trust service meshes and HTTP middleware with centrally-managed policy-as-code powered by EOPA. How is a hard-working supervillain supposed to make ends meet these days?
As for you? Your job is done for now, the fruits of your Athena queries passed off to the IAM and compliance teams. Your laptop closes with a gentle thunk as you return to your bed for a few more hours of hard-earned shuteye.
Conclusion
In this post, you learned how to configure Enterprise OPA to store decision logs in AWS S3 via Enhanced Decision Logging, as well as how to query that data using AWS Athena. You should now have a strong foundation for your EOPA decision log querying needs, from enterprise security breach analysis to business intelligence. From this starting point, you can create more complex SQL queries against your decision logs that will run entirely in AWS’s Trino+Presto-based Athena tool.
Going forward, you can find more information in the documentation linked below. You may want to experiment with different configurations of EOPA, especially the decision log batch size and buffer settings to optimize for your data durability and performance needs.
References: