Three-Body Problem for Policy: Policy, Data and Software
In the early days of Styra when we were creating Open Policy Agent (OPA), we had a singular goal in mind: help engineers enforce any policy over any piece of software. We wanted people to be able to write any policy they’d like, whether it be about complex resources managed by Kubernetes or public cloud, APIs routed through gateways or service meshes, data stored in relational or document databases, application deployments controlled by CICD pipelines, and so on. Moreover, we wanted people to enforce those policies with any piece of software, integrating as an in-process library, a near-process sidecar or host-local daemon, or a beefier centralized service. So obviously we aimed for tremendous flexibility in terms of the policies and the software they would be integrated into.
One key observation we made very quickly is that a policy itself often depends on external data —information about the world outside of the policy system. You can’t evaluate a simple policy like “only the owner of a resource can delete that resource” if you don’t know who the resource’s owner actually is. So we added another requirement that OPA should work with really any kind of data.
Those goals are reflected quite clearly in the diagram we use to show OPA and how it works:
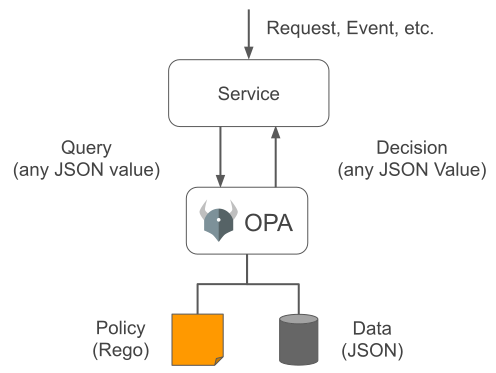
The challenge of course is that with so much flexibility you have many options to sort through when solving a real-world policy-enforcement problem.
- Which policies do you want to enforce?
- Where do you want to enforce them?
- How do you get the relevant data to OPA?
In this blog post we discuss how all three of those questions have interrelated answers, as illustrated by the diagram below. This three-way dependency is reminiscent of the three-body problem in physics — how the mass and velocity of three independent bodies (e.g. planets) all influence each other and what we want is to understand how they behave as a whole. There is no closed-form solution (i.e. there is no formula or logical expression) that tells you the velocity of all three bodies at any point in time; instead the only known solution is to iteratively compute how they interact in small time increments. The same kind of holds for designing a policy solution: there’s no simple answer to choosing the policy, data, and software to solve your problem. You need to understand how they interact and iteratively refine your design until you have a stable solution.
Of course, to make things easier it’s helpful to see the solutions that others have found. In subsequent blog posts we aim to describe a handful of design patterns that illustrate stable solutions to policy problems and how you can apply them too. This blog post provides the background to understand those design patterns through the lens of a solution to the policy three-body problem.
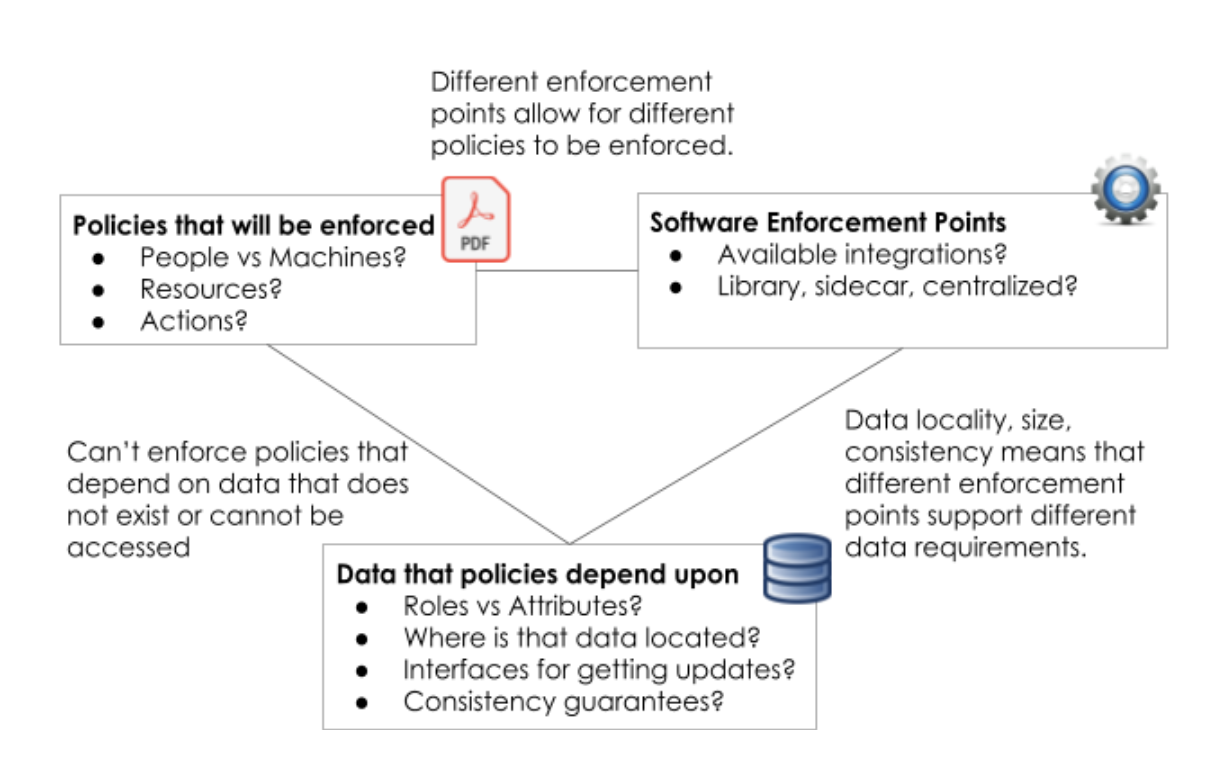
Policy – Software – Data
As shown in the diagram above, all three of these ideas: what policy to enforce, where that policy is enforced, and what data the policy depends on are all related to each other. To be more specific though let’s clarify what we mean by each.
Policy: logic that makes a decision based on some input it is provided. For example, a policy for a pet adoption application might say
an adoptable pet may be marked as adopted only by its current owner
any user may read the photo, species, breed, age for each pet but not the current owner’s name, address, or email
a developer of the pet adoption application who is on-call with a P1 ticket assigned to her can read all information for all pets (for debugging purposes)
Whenever someone tries to mark a pet as adopted, the policy itself does not know who the current owner of that pet is. Nor does the policy itself know which users are employees. All that information must be provided to the policy.
Software: One way that information is provided is as part of the request for a decision made by the real-world software system. For example, Alice is trying to mark pet352 (named “Lassie”) as adopted and the software that will execute that change needs an authorization decision. That software provides all that information to the policy and asks for a policy decision. For example, that software might provide only the following information
username (e.g. “alice”)
groups the user is a member of (e.g. “customers”)
identification for the software asking for a decision (e.g. a SPIFFE identifier like spiffe://petadopt.com/portal)
action being performed (e.g. “markAdopted”)
resource it is performed on (e.g. “pet352”)
Crucially, it is the software that creates the policy request and therefore that controls what information is included in that request.
Data. Some policies require information not contained within the policy request. This (external) data is no less important for making a decision; it’s just that for some (often good) reason it’s not included as part of the request. Examples here include:
attributes of resources, such as who the owner of a resource is (e.g. “bob” is the current owner of “pet352”)
attributes of people, such as the list of people currently on-call
technical context, such as whether there’s an open ticket
business context, such as how soon Black Friday is upon us
External data can have a wide array of physical locations, technologies, sizes, dynamicities and consistency guarantees.
Inter-relationships
Policy, Data and Software are interrelated in the sense that if you make a design decision about one of them, that decision influences the other two. As I mentioned above, this reminds me of the three-body problem in physics — how three independent bodies all influence each other and what we want is to understand how they behave as a whole. Just as in physics, here we describe how each pair influences each other.
Policy & Data. This we’ve already discussed — that the policies you want to write depends on data. You can’t evaluate the policy “only the current owner can mark a pet as adopted” if you don’t know who owns which resource. Similarly, if you know what data is available, you also know what kinds of policies you can evaluate. Given the list of current pet owners, you could write the following policy:
owners can modify their pets’ information
owners can read their pets’ information
non-owners can read all pets’ information
In the end, fundamentally, Policy and Data are both needed to make decisions and in so doing guide the behavior of software systems.
Software & Policy. The software that enforces policy decisions has a dramatic impact on what policies can be enforced. Similarly, depending on the policy you want to enforce, you need to choose the correct architectural control point.
An API gateway enables you to enforce API policies over end-user (aka north-south) actions.
A service mesh enables you to enforce API policies over end-user (aka north-south) actions, service-to-service (aka east-west) actions and egress traffic.
A database enables you to enforce data-protection policies at the table-level, row-level, column-level and sub-document-level.
Kubernetes and public cloud enable you to enforce configuration policies over fields in deeply-nested resource hierarchies.
Choose the software enforcement point, and that will limit what policies you can enforce. And vice versa, if you know what policy you need to enforce, that will limit which software you can enforce it from.
Software and Data. Data gravity is an age-old problem. Not all data can be made available to all software enforcement points because of the data’s size, dynamicity, consistency requirements and so on. To make data available for policy enforcement means understanding where the source of truth for that data is, how to get access to it, what portion of it can be shipped to the software’s location and be kept sufficiently up to date and safe.
An API Gateway typically cannot store a terabyte of resource attributes.
A service mesh cannot store a copy of LDAP on every node in the mesh.
If you choose a software enforcement point, be sure you can ship the data to it that you need. Vice versa, if you know what data requirements you have, that’ll limit what software you can ship it to.
The important takeaway here is that you have three different design decisions to make: which policies to enforce, which data to rely on and which software to use to enforce those policies. And that those decisions, perhaps not surprisingly, influence each other. So whenever you’re putting a new solution in place, you may need to go through an iterative design process where you pick the ones that you’re most sure of, work through the others and then take a step back to decide whether they all make sense together, before making another editing pass.
Summary
This blog post covers the background you need to understand three key design decisions about policy enforcement (Policy – Data – Software) and how they relate to each other.
Policies can only be evaluated when provided with the correct data.
Data gravity (size, dynamicity, and consistency) influence which Software can practically be used to make policy decisions using that data.
Software that is integrated with OPA determines which domain of policy decisions can be made and enforced (e.g. API, Data, Resource configuration).
This post is the first in a series that details some of the design patterns for policy enforcement that we have found in the wild and that balance these three design decisions. In future posts, we will describe each of the following design patterns:
Offline configuration: Authorization for platform resources that are managed outside of the platform itself.
Online configuration: Authorization for platform resources that are managed only within the platform.
Application sidecar: Authorization for end-users or services whose policies are written entirely by developers.
Application entitlements: Authorization for employees who are granted permissions based on traditional systems-of-record (e.g. LDAP).
Application multi-tenancy: Authorization for end-users who write the policies that the system enforces.
Interested in learning more about OPA? Sign up for the Styra Academy! It’s a free online portal that provides exclusive Open Policy Agent, Rego and Styra DAS training from the founders of Styra and OPA!